Event Loop изнутри: от браузера до Node.js
Часть 1. Браузер VS сервер.
Вопрос c собеседований
Наверняка, вы не раз слышали один из любимых вопросов интервьюеров: “Расскажите про Event Loop в JavaScript”. Как правило, речь идёт про браузерную версию JavaScript. И если нужен простой ответ, он может звучать так:
Event Loop – это механизм, который позволяет JavaScript, будучи однопоточным, обрабатывать асинхронные операции. Он работает со стеком вызовов (Call Stack) и двумя очередями задач – Microtask Queue (для микрозадач) и Task Queue (для макрозадач).
Если объяснять проще, у нас есть три типа операций:
- Синхронный код – выполняется сразу в Call Stack.
- Микрозадачи – Promise.then(), выполняются сразу после синхронного кода.
- Макрозадачи – setTimeout / setInterval, выполняются последними.
Запомнить порядок просто:
- Сначала синхронный код – он выполняется прямо сейчас, без ожиданий.
- Потом микрозадачи – например, обработка ответа с бэкенда важнее, чем скрытие уведомления.
- Завершают очередь макрозадачи – например, закрытие нотификации через setTimeout.
Этих знаний уже достаточно, чтобы уверенно отвечать на вопрос “Что и в каком порядке выведется в консоль при выполнении вот такого кода?”.
Да, в микрозадачах и макрозадачах есть другие механизмы помимо Promise и setTimeout, и сам Event Loop устроен сложнее, чем кажется на первый взгляд. Но пока этого достаточно.
А зачем нам Loop?
Глобально, Event Loop решает важную задачу – позволяет асинхронно выполнять операции в однопоточном JavaScript, создавая иллюзию многопоточности.
Представим, что у нас есть веб-сервер, который обрабатывает входящие HTTP-запросы. Например, при запросе к определённому API-роуту сервер делает запрос в базу данных и возвращает результат.
Без механизма асинхронного выполнения, пока сервер ждёт ответа от базы данных, он был бы заблокирован – не мог бы обрабатывать другие запросы, даже если процессор при этом простаивает.
Какие есть варианты решения этой проблемы?
- Многопоточность – подход, который использовал Apache. Он мог создавать отдельный процесс или поток на каждый запрос. Чем больше запросов, тем больше ресурсов тратилось на поддержку этих процессов/потоков, что быстро упиралось в лимиты памяти.
- Неблокирующий ввод/вывод (Non-blocking I/O) – подход, на котором основан Nginx и, собственно, Event Loop в JavaScript. Вместо создания отдельных потоков, операции выполняются асинхронно, и когда одна задача “ждёт” (например, загрузку данных), CPU может заняться другими задачами.
В чём принципиальная разница?
Ресурсы тратятся в обоих случаях, но разница в том, на что именно. При многопоточном подходе колоссальный объем оперативной памяти уходит на само содержание тысяч спящих потоков, ожидающих ответа (от файлов, БД или сети), а процессор тратит мощности на переключение между ними (context switching). При неблокирующем подходе один поток не простаивает в ожидании: он регистрирует событие и тут же переключается на полезную работу по другому запросу. Ресурсы идут на саму работу, а не на поддержку ожидания.
Event Loop делает это возможным, управляя очередями задач и освобождая основной поток для выполнения других операций. Это позволяет, в частности, серверу на Node.js обрабатывать тысячи соединений одновременно, даже несмотря на то, что он формально работает в однопоточном режиме.
Чем Event Loop в Node.js отличается от Event Loop в браузере?
Мы разобрали, как работает Event Loop в браузере. Теперь пришло время взглянуть на него в Node.js.
Базовые принципы схожи: есть синхронный код, макро- и микрозадачи. Но различия начинаются уже с того, как именно обрабатываются макрозадачи – в Node.js они проходят через шесть фаз вместо одной общей очереди.
Вот последовательность этих фаз:
- Timers – выполняются колбэки, запланированные через
setTimeout()иsetInterval(). - Pending Callbacks – выполняются колбэки операций, которые отложены по системным причинам (например, ошибки TCP).
- Idle, Prepare – внутренняя фаза движка V8.
- Poll – главная фаза ввода-вывода: здесь выполняются I/O-операции (
fs.readFile, сетевые запросы и т. д.). Если дальше задач нет, Event Loop может здесь зависнуть и ждать новых событий. - Check – выполняются колбэки
setImmediate(). - Close Callbacks – обрабатываются колбэки закрытия (
socket.on('close')).
Но это ещё не всё. После каждой из этих фаз выполняется очередь микрозадач – Promise.then(), queueMicrotask(), а также… таинственный process.nextTick(), который вообще не является микрозадачей и выполняется раньше них.
Шесть фаз, микрозадачи, nextTick() – как это всё запомнить и понять, что когда выполняется? Давайте разбираться.
Порядок фаз в Event Loop
Для начала отбросим две менее интересные для нас фазы – “Pending Callbacks” и “Idle, Prepare”. Они редко встречаются в реальных сценариях, поэтому сосредоточимся на четырёх ключевых фазах, которые можно увидеть вживую в коде.
Разберёмся, как именно Node.js проходит через эти фазы, на конкретном примере:
const fs = require("fs");
console.log("🟢 1. Начало синхронного кода");
// 🔹 Микрозадачи и nextTick
process.nextTick(() => console.log("⚡ nextTick"));
Promise.resolve().then(() => console.log("⚡ Promise.then"));
// 🔹 Таймер (Timers Phase)
setTimeout(() => console.log("⏳ setTimeout (Timers Phase)"), 0);
// 🔹 setImmediate (Check Phase)
setImmediate(() => console.log("⏩ setImmediate (Check Phase)"));
// 🔹 I/O операция (Poll Phase)
fs.readFile(__filename, () => {
console.log("📂 fs.readFile (Poll Phase)");
});
// 🔹 Событие закрытия (Close Callbacks Phase)
const readable = fs.createReadStream(__filename);
readable.close();
readable.on("close", () => console.log("🚪 onClose (Close Callbacks Phase)"));
console.log("🟢 2. Конец синхронного кода");
Этот код даёт следующий порядок вывода:
🟢 1. Начало синхронного кода
🟢 2. Конец синхронного кода
⚡ nextTick
⚡ Promise.then
⏳ setTimeout (Timers Phase)
⏩ setImmediate (Check Phase)
🚪 onClose (Close Callbacks Phase)
📂 fs.readFile (Poll Phase)
Что здесь важно заметить:
- Сначала выполняется весь синхронный код, ещё до того, как запускается Event Loop.
- После этого выполняются микрозадачи и
nextTick:process.nextTick()– это самая приоритетная очередь, она выполняется первой.Promise.then()– микрозадача, выполняется сразу послеnextTick.
- Только после этого запускается сам Event Loop, который проходит через основные фазы.
Чтобы было проще воспринимать процесс, представим его в виде таблицы:
| Фаза Event Loop | Итерация 1 | Итерация 2 |
|---|---|---|
| Timers Phase (setTimeout 0) | ✔ | |
| Poll Phase (I/O, fs.readFile) | ✔ | |
| Check Phase (setImmediate) | ✔ | |
| Close Callbacks Phase (onClose) | ✔ |
Фазы и ключевые итерации Event Loop
Почему Poll Phase (fs.readFile()) оказалась во второй итерации?
Потому что Node.js требуется время, чтобы прочитать файл, и эта операция не успевает выполниться в первую итерацию Event Loop.
Почему onClose() выполнился в первой итерации?
Потому что readable.close() был вызван ещё в синхронном коде, и onClose() уже был готов к выполнению в Close Callbacks Phase.
Теперь усложним наш пример. Добавим в обработчик fs.readFile() несколько новых операций:
// 🔹 I/O операция (Poll Phase)
fs.readFile(__filename, () => {
console.log("📂 fs.readFile (Poll Phase)");
setTimeout(() => console.log("⏳ setTimeout внутри fs.readFile"), 0);
setImmediate(() => console.log("⏩ setImmediate внутри fs.readFile"));
process.nextTick(() => console.log("⚡ nextTick внутри fs.readFile"));
});
Порядок вывода будет таким:
🟢 1. Начало синхронного кода
🟢 2. Конец синхронного кода
⚡ nextTick
⚡ Promise.then
⏳ setTimeout (Timers Phase)
⏩ setImmediate (Check Phase)
🚪 onClose (Close Callbacks Phase)
📂 fs.readFile (Poll Phase)
⚡ nextTick внутри fs.readFile
⏩ setImmediate внутри fs.readFile
⏳ setTimeout внутри fs.readFile
Какие изменения:
- Все предыдущие операции выполняются в таком же порядке, что и раньше.
- Добавился новый
nextTick, который выполняется сразу послеfs.readFile(), но до других операций в этом обработчике. setImmediate()внутриfs.readFile()выполняется раньшеsetTimeout(), потому что Check Phase идёт перед Timers Phase.
Обновим таблицу с фазами:
(Фазы и ключевые итерации Event Loop в обновленном примере)
| Фаза Event Loop | Итерация 1 | Итерация 2 | Итерация 3 |
|---|---|---|---|
| Timers Phase (setTimeout 0) | ✔ | ✔ | |
| Poll Phase (I/O, fs.readFile) | ✔ | ||
| Check Phase (setImmediate) | ✔ | ✔ | |
| Close Callbacks Phase (onClose) | ✔ |
Почему nextTick внутри fs.readFile() сработал сразу?
Потому что process.nextTick() не зависит от фаз Event Loop. Он выполняется прямо после текущего колбэка (в данном случае, колбэка fs.readFile), до перехода к следующей фазе цикла или выполнению остальных микрозадач.
Выводы
Мы разобрались, что Event Loop – это сердце асинхронности в JavaScript, которое позволяет нам не блокировать выполнение кода и обрабатывать задачи в правильном порядке. Погрузились в отличия между Event Loop в браузере и Node.js и на примере прошлись по фазам Event Loop, разобравшись, в каком порядке выполняются таймеры, колбэки I/O, setImmediate и прочие важные вещи.
Однако, мы не затронули кучу интересных тем, например:
- Что делает
libuvи как это связано с Event Loop? - Можно ли реально предсказать порядок выполнения кода во всех случаях?
- Что происходит в фазах “Pending Callbacks” и “Idle, Prepare”?
- Когда Node.js успевает читать файлы, если Poll Phase обрабатывает только готовые I/O события?
- Как работают серверы на Node.js, и правда ли, что если один запрос завис, то весь сервер “повиснет” и перестанет принимать другие?
- Если Node.js однопоточный, то как он работает на многоядерных компьютерах?
- И можно ли сделать Node.js реально многопоточным?
Event Loop, да и сам Node.js — это глубокая тема, и мы только начали разбираться в его механиках.
Часть 2. Нюансы работы Event Loop.
Предсказать порядок выполнения
Кажется, что если фазы Event Loop следуют строго друг за другом, то порядок выполнения кода можно легко предсказать. Но это не всегда так.
Один из примеров — setTimeout(0) и setImmediate().
setTimeout(() => console.log("⏳ setTimeout"), 0);
setImmediate(() => console.log("⏩ setImmediate"));
Интуитивно можно подумать, что setTimeout(0) сработает раньше, ведь Timers Phase идёт первой. Однако, если запустить этот код, результат может отличаться от раза к разу:
⏳ setTimeout
⏩ setImmediate
или
⏩ setImmediate
⏳ setTimeout
Почему так происходит?
Event Loop проходит через фазы в следующем порядке:
Timers → Pending Callbacks → Idle, Prepare → Poll → Check → Close Callbacks
setTimeout(0)выполняется в Timers Phase, которая запускается в начале новой итерации Event LoopsetImmediate()выполняется в Check Phase, которая идёт сразу после Poll.
Но для того, чтобы setTimeout(0) попал в очередь выполнения, системе нужно некоторое время. Если Event Loop уже переключился на Poll и обнаружил, что больше задач нет, он сразу переходит к Check Phase, где выполняется setImmediate(). А setTimeout(0), если не успел обработаться в первой итерации, будет ждать следующего цикла.
Из этого следует и то, что задержка в setTimeout() — это не гарантированное время выполнения, а минимальное время ожидания перед запуском колбэка.
Однако, если запустить те же операции внутри I/O-коллбэка, порядок всегда предсказуем:
fs.readFile(__filename, () => {
setTimeout(() => console.log("⏳ setTimeout"), 0);
setImmediate(() => console.log("⏩ setImmediate"));
});
Когда код выполняется внутри I/O-коллбэка, Event Loop уже находится в Poll Phase. После обработки Poll Phase всегда наступает Check Phase (где выполняется setImmediate()), а только затем, на следующей итерации, Timers Phase (setTimeout(0)).
Что на самом деле происходит в фазах “Pending Callbacks” и “Idle, Prepare”
Ранее мы обошли эти две фазы стороной, но теперь разберёмся, какую роль они играют в Event Loop.
Фаза Pending Callbacks выполняется сразу после Timers Phase и перед Idle, Prepare Phase. Её основная задача — обработать отложенные системные колбэки, которые не относятся к таймерам или I/O, но требуют выполнения в ближайшем цикле. По сути, это буфер для событий, которые не могут быть обработаны в Poll Phase. Без неё ошибки могли бы потеряться или выполняться с задержкой. Например, сюда попадают ошибки в TCP/UDP-соединениях.
Пример кода, в котором можно увидеть эту фазу в работе:
const fs = require("fs");
const net = require("net");
console.log("🟢 1. Начало синхронного кода");
// 🔹 Ошибка в TCP-соединении (Pending Callbacks Phase)
const socket = net.connect(9999, "127.0.0.1"); // Не существует
socket.on("error", () => console.log("📌 Pending Callbacks Phase: TCP ошибка"));
// 🔹 setTimeout (Timers Phase)
setTimeout(() => console.log("⏳ setTimeout (Timers Phase)"), 0);
// 🔹 setImmediate (Check Phase)
setImmediate(() => console.log("⏩ setImmediate (Check Phase)"));
// 🔹 I/O операция (Poll Phase)
fs.readFile(__filename, () => {
console.log("📂 fs.readFile (Poll Phase)");
});
// 🔹 Закрытие потока (Close Callbacks Phase)
const readable = fs.createReadStream(__filename);
readable.close();
readable.on("close", () => console.log("🚪 onClose (Close Callbacks Phase)"));
console.log("🟢 2. Конец синхронного кода");
Порядок вывода будет такой:
🟢 1. Начало синхронного кода
🟢 2. Конец синхронного кода
⏳ setTimeout (Timers Phase)
📌 Pending Callbacks Phase: TCP ошибка
⏩ setImmediate (Check Phase)
🚪 onClose (Close Callbacks Phase)
📂 fs.readFile (Poll Phase)
Как видно, TCP-ошибка срабатывает после Timers Phase, но до остальных фаз.
Фаза Idle, Prepare — это техническая фаза Event Loop, а точнее, две фазы, которые часто рассматривают как одну. Они выполняются сразу после Pending Callbacks, перед Poll Phase, и используются исключительно внутри движка Node.js. В них нельзя напрямую записывать колбэки, поэтому они редко упоминаются.
- Idle Phase отвечает за ожидание новых задач, если в Poll Phase пока ничего нет.
- Prepare Phase используется для подготовки событий перед Poll Phase, например, планирование будущих I/O-операций.
Эти фазы остаются «за кулисами» работы Node.js, но играют важную роль в том, как Event Loop управляет асинхронностью.
Зачем нужен process.nextTick()
Мы уже говорили, что process.nextTick() — это механизм, который позволяет выполнять код немедленно после завершения текущего выполнения, но до выхода в Event Loop. При этом он имеет приоритет даже перед микротасками. Но если у нас уже есть Promise.then() и setImmediate(), зачем нужен ещё один способ отложенного выполнения?
На первый взгляд, Promise.then() тоже выполняется до макрозадач и кажется, что его можно использовать вместо nextTick(). Однако в Node.js есть задачи, которые требуют выполнения строго перед любыми другими операциями. Например, обработка ошибок. Если внутри асинхронной функции произошла ошибка, её обработчик должен выполниться до любых других задач, чтобы не допустить некорректного состояния программы. process.nextTick() гарантирует, что этот код выполнится раньше, чем любые другие операции, даже если в очереди уже есть Promise.then(). Если бы обработка ошибки была запланирована через микротаски, она могла бы выполниться позже других асинхронных операций, что в некоторых случаях могло бы привести к трудноуловимым багам.
Другой важный случай использования process.nextTick() — серверные приложения. Например, когда мы вызываем server.listen(), сервер может мгновенно привязаться к порту и начать принимать соединения. В это время обработчик события "listening" может быть ещё не вызван. Если клиент подключится сразу после запуска, есть вероятность, что "connection" сработает до "listening", что выглядит нелогично.
Пример:
const net = require("net");
const server = net.createServer();
server.listen(8080);
server.on("listening", () => {
console.log("👂 Сервер запущен и слушает порт 8080");
});
server.on("connection", (conn) => {
console.log("🔗 Новое соединение!");
});
В этом коде, если Event Loop пойдёт в Poll Phase раньше, чем обработается "listening", сервер может уже принять соединение. Это может привести к тому, что "connection" сработает до того, как мы узнаем, что сервер запущен.
Тогда мы могли бы получить такой странный вывод:
🔗 Новое соединение!
👂 Сервер запущен и слушает порт 8080
Использование process.nextTick() для обработчика "listening" гарантирует, что сервер корректно уведомит о своём запуске до того, как начнёт обрабатывать соединения.
Как зациклить Node.js
Несмотря на удобство process.nextTick(), его нельзя использовать слишком часто, потому что он может заблокировать Event Loop. Если бесконечно ставить новые process.nextTick() внутри уже выполняющегося колбэка, Event Loop никогда не дойдёт до следующих фаз, и код просто зависнет:
function infiniteTick() {
console.log("⚠ Бесконечный nextTick");
process.nextTick(infiniteTick);
}
infiniteTick();
Этот код зависнет, потому что process.nextTick() выполняется до любых других фаз, и Event Loop никогда не перейдёт к следующим операциям.
Именно поэтому process.nextTick() стоит использовать осознанно, только в тех ситуациях, когда Promise.then() или setImmediate() не дают нужного эффекта.
Интересно также, что в браузере process.nextTick() отсутствует, и на это есть важная причина. В отличие от Node.js, браузерный Event Loop управляет не только выполнением JavaScript, но и отрисовкой интерфейса, обработкой пользовательских событий и другими критическими задачами. Если бы браузер поддерживал process.nextTick(), разработчики могли бы случайно заблокировать интерфейс, вызывая nextTick() бесконечно. Это сделало бы страницу полностью зависшей, так как Event Loop не смог бы переключиться на обработку рендеринга. В браузерах эту функцию заменяют микротаски, которые выполняются до макрозадач, но не блокируют обновление интерфейса.
Выводы
Во второй части мы углубились в более сложные аспекты Event Loop и разобрали те ситуации, в которых порядок выполнения кода может быть не таким очевидным, как кажется. Мы выяснили, почему setTimeout(0) и setImmediate() иногда меняются местами, как на самом деле работают фазы Pending Callbacks и Idle, Prepare, а также разобрались, почему в браузерах нет process.nextTick().
Кроме того, мы увидели, что process.nextTick() — это не просто более приоритетная микротаска, а инструмент, который критически важен для правильного порядка выполнения кода в Node.js. С его помощью можно корректно обрабатывать ошибки, управлять серверными соединениями и гарантировать выполнение важного кода до выхода в Event Loop.
За кулисами остаётся ещё много интересных тем. Чем глубже мы погружаемся в Event Loop, тем больше вопросов возникает. Но это только делает изучение Node.js ещё интереснее.
Часть 3. За пределами Event Loop.
Что такое libuv
До этого момента мы говорили про Event Loop как про некий волшебный механизм, который позволяет Node.js выполнять асинхронный код. Но на самом деле сам JavaScript не умеет ни читать файлы, ни слушать порты. Всем этим занимается libuv — C-библиотека, которая скрывается под капотом Node.js и делает всю грязную работу.
Именно libuv реализует Event Loop, а заодно берёт на себя кучу других задач: работу с файловой системой, сетевыми соединениями, DNS, асинхронным вводом-выводом и даже многопоточностью. Всё это работает прозрачно: мы пишем асинхронный JS-код, а libuv под капотом разруливает, когда, где и каким потоком обработать операцию.
И “магия”, когда fs.readFile() не блокирует выполнение, а просто вызывает callback через пару миллисекунд, — это результат работы libuv, о чём мы поговорим дальше.
В каком-то смысле libuv — это “двигатель”, который приводит Event Loop в движение и заодно отвечает за всё, что происходит вне самого JavaScript. Без него Node.js не был бы асинхронным. И теперь, когда мы уже разобрались, как устроен Event Loop на верхнем уровне, пришло время заглянуть чуть глубже — туда, где всё крутится на самом деле.
Когда Node.js успевает читать файлы
Мы видели, что в фазах Event Loop обрабатываются результаты I/O-операций — например, callback fs.readFile() срабатывает в Poll Phase, когда данные уже готовы. Но когда происходит само чтение файла? Ведь внутри цикла нет “фазы чтения”, да и в Event Loop мы нигде явно не видим, что идёт доступ к диску.
На самом деле, это и не обязанность Event Loop — эту работу за него делает libuv. Когда мы вызываем fs.readFile(), Node.js не начинает читать файл прямо в текущем потоке. Вместо этого задача отправляется в фоновый thread pool, где и происходит чтение. По завершении операции результат “возвращается” в Event Loop — и только тогда срабатывает callback.
Thread pool — это набор фоновых потоков, которые Node.js использует для выполнения тяжёлых задач вне основного потока. Когда нужно прочитать файл, посчитать хэш или сжать данные, задача отправляется в один из потоков пула.
Таким образом, всё тяжёлое происходит параллельно, а Event Loop лишь обрабатывает уведомление “готово!”. Это позволяет JS-коду не блокироваться и выполнять другие задачи, пока файл читается где-то в фоне.
Что ещё работает так же?
Не только работа с файлами уходит в фон. Вот список встроенных модулей, задачи в которых тоже уходят в thread pool:
fs.*— чтение и запись файлов (readFile,writeFile,stat, и т. д.);zlib.*— сжатие и распаковка данных (gzip,deflate,gunzip, и т. д.);crypto.pbkdf2,crypto.scrypt— ресурсоёмкие криптографические операции;dns.lookup— разрешение доменных имён в IP-адреса.
А сколько таких фоновых потоков?
По умолчанию — 4. Это значит, что если мы одновременно запустим 10 раз crypto.pbkdf2(), первые 4 выполнятся сразу, а остальные встанут в очередь:
const crypto = require("crypto");
const start = Date.now();
function runTask(id) {
crypto.pbkdf2("password", "salt", 100_000, 64, "sha512", () => {
const time = Date.now() - start;
console.log(`🔐 Задача ${id} завершена через ${time} мс`);
});
}
// Запускаем 10 тяжёлых задач
for (let i = 1; i <= 10; i++) {
runTask(i);
}
Вывод, который мы получим по умолчанию:
🔐 Задача 1 завершена через 31 мс
🔐 Задача 2 завершена через 37 мс
🔐 Задача 4 завершена через 37 мс
🔐 Задача 3 завершена через 37 мс
🔐 Задача 5 завершена через 62 мс
🔐 Задача 7 завершена через 64 мс
🔐 Задача 6 завершена через 64 мс
🔐 Задача 8 завершена через 68 мс
🔐 Задача 9 завершена через 91 мс
🔐 Задача 10 завершена через 92 мс
Здесь мы видим, что задачи завершаются группами (пулами по 4), с задержкой между ними.
Лимит потоков можно изменить через переменную окружения: UV_THREADPOOL_SIZE=8 node app.js.
Теперь одновременно выполнятся 8 задач — и вывод в консоли будет идти плотнее (группами по 8):
🔐 Задача 7 завершена через 35 мс
🔐 Задача 8 завершена через 41 мс
🔐 Задача 5 завершена через 43 мс
🔐 Задача 3 завершена через 44 мс
🔐 Задача 6 завершена через 46 мс
🔐 Задача 1 завершена через 48 мс
🔐 Задача 4 завершена через 50 мс
🔐 Задача 2 завершена через 54 мс
🔐 Задача 9 завершена через 67 мс
🔐 Задача 10 завершена через 71 мс
Значение можно поднять до 1024, но чаще всего 8–16 достаточно с головой. Главное — помнить, что thread pool не бесконечный и перегружать его не стоит.
Стоит отметить, что порядок завершения задач может не совпадать с порядком их запуска. Это связано с тем, что операции выполняются параллельно в разных потоках, и точное время завершения зависит от множества факторов — загрузки системы, особенностей запуска потока, внутреннего распределения задач. В результате некоторые задачи, начатые позже, могут завершиться раньше. Это нормальное и ожидаемое поведение многопоточной обработки.
А как же многоядерные процессоры?
Node.js традиционно считается однопоточным, потому что весь JavaScript-код выполняется в одном потоке — внутри Event Loop. Но это не значит, что он не может использовать мощность многоядерных систем.
Во-первых, libuv использует thread pool для тяжёлых операций (чтение файлов, криптография, сжатие), и каждый поток из этого пула может выполняться на своём ядре. Таким образом, параллельная работа уже есть — просто не в самом JS-коде.
Во-вторых, Node.js предоставляет собственные инструменты для распараллеливания задач: cluster и worker_threads. Каждый такой поток может также работать на отдельном ядре.
По итогу Node.js все же использует несколько ядер, и в каких-то случаях мы даже можем этим управлять.
Как не заблокировать Node.js
Если начать активно загружать thread pool тяжёлыми задачами или использовать синхронные методы, можно легко заблокировать Event Loop или заставить задачи ждать слишком долго.
Вот несколько практических рекомендаций, основанных на официальной документации Node.js:
- Избегать синхронных методов из модулей
fs,crypto,zlib, особенно в коде, который обрабатывает входящие запросы. Например,fs.readFileSync()может заморозить весь сервер, пока не прочитает файл. - Не запускать слишком много тяжёлых операций одновременно, особенно если они идут в thread pool. Например, десятки
crypto.pbkdf2()илиzlib.gzip()в одном цикле забьют очередь и часть задач просто будет ждать освобождения потока. - Увеличивать размер пула, если задача действительно требует параллельной обработки большого числа I/O-операций. Это можно сделать через переменную
UV_THREADPOOL_SIZE. Однако больше не всегда лучше, ведь каждый дополнительный поток несёт и дополнительные накладные расходы.
Также стоит быть осторожными с регулярными выражениями и JSON.parse(). Они выполняются синхронно, прямо в основном потоке, и если регулярка слишком сложная, а JSON слишком большой — Event Loop встанет. Особенно критично это становится, если такие операции попадают в код обработки пользовательских запросов.
И здесь мы подбираемся к отдельной категории проблем — не только про производительность, но и про безопасность.
Что такое REDOS и как он может положить сервер
REDOS (Regular Expression Denial of Service) — это атака, при которой злоумышленник отправляет специально сконструированную строку, вызывающую крайне медленную обработку регулярного выражения. Выполнение такой регулярки в основном потоке приводит к блокировке работы всего сервера Node.js.
Пример:
// Уязвимая регулярка
const regex = /(a+)+$/;
const input = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaX";
input.match(regex); // может зависнуть
Выглядит этот код, кажется, нормально, но стоит добавить в конец строки “X”, и движок регулярных выражений начинает бесконечно перебирать все возможные пути сопоставления, чтобы понять, почему X не подходит. Чем длиннее строка, тем дольше он “думает”.
При этом всё это происходит прямо в Event Loop, который блокируется и не может обрабатывать ни другие запросы, ни таймеры, ни события.
Как защититься от REDOS:
- Не использовать регулярки с вложенными квантификаторами, особенно
(a+)+,(.*)+,(.+)+и им подобные. - Проверять пользовательский ввод заранее, если он попадёт в регулярное выражение.
- Ограничивать размер входных данных — это справедливо и для JSON, и для строк.
- Использовать инструменты для проверки потенциально опасных шаблонов.
- Если есть сомнения — не использовать регулярку вовсе, а обрабатывать данные через индекс поиска,
splitи т. п.
Хоть в этой части мы и говорили преимущественно про работу thread pool, важно помнить: все задачи в Node.js стартуют с Event Loop. И если Event Loop завис — никакие потоки не спасут, никакие таймеры не сработают, сервер не примет новые соединения. Ничего не произойдёт. Поэтому беречь Event Loop — это не просто хорошая практика. Это крайне важно, когда вы работаете с Node.js.
Выводы
В этой части мы заглянули под капот Event Loop и впервые по-настоящему познакомились с libuv — той самой библиотекой, которая делает возможной асинхронность в Node.js. Мы выяснили, что Event Loop сам не читает файлы, не шифрует данные и не делает запросы, а лишь координирует выполнение задач, передавая их в thread pool, который работает параллельно.
На реальных примерах посмотрели, как fs.readFile, crypto.pbkdf2 и другие встроенные модули уходят в фоновую очередь, и почему одновременно выполняются только 4 такие задачи. А заодно — что может пойти не так, если нагрузить этот пул по полной. Также разобрали, почему даже одна тяжёлая синхронная операция может “повесить” всё приложение, и как это связано с REDOS-атакой, при которой регулярка, написанная в спешке, может положить весь сервер.
Самое важное, что становится очевидным: даже с thread pool и фоновыми процессами Event Loop остаётся сердцем приложения. Он запускает задачи, принимает соединения, обрабатывает события. И если он зависнет — всё остальное встанет.
Часть 4. HTTP-сервер
Как работает сервер на Node.js
Когда мы пишем:
const http = require('http');
const server = http.createServer((req, res) => {
res.end('Hello, world!');
});
server.listen(3000);
…кажется, что Node.js просто вызывает нашу функцию, когда кто-то стучится на порт. Но на самом деле всё чуть глубже.
Вызов http.createServer() — это просто обёртка над net.createServer(), по факту мы работаем с обычным TCP-соединением. Далее Node.js сам парсит заголовки, собирает req, res и передает их в наш callback. Но тот же самый пример можно реализовать и вот так:
const net = require('net');
const server = net.createServer((socket) => {
socket.write('HTTP/1.1 200 OK\r\n');
socket.write('Content-Type: text/plain\r\n');
socket.write('Content-Length: 13\r\n');
socket.write('\r\n');
socket.write('Hello, world!');
socket.end();
});
server.listen(3000);
Здесь мы сами отвечаем по протоколу HTTP — просто шлём строку. Это всё ещё TCP, просто ручной режим и отсутствие привычных req и res.
А кто вообще следит за портом?
Когда мы вызываем server.listen(), Node.js передаёт порт библиотеке libuv, которая и занимается всей I/O-магией. Она регистрирует сокет в системе и говорит: «ОС, скажи, когда на этот порт кто-нибудь постучится». В разных операционных системах для этого используются разные системные вызовы.
Сам Node.js ничего не «слушает» вручную — он просто ждёт от ОС сигнал, что появилось соединение.
Так в какой фазе Event Loop работает сервер?
Когда соединение приходит, Node.js добавляет обработку в Event Loop — не мгновенно, а в очередь. Это значит, что сначала выполнятся все nextTick и Promise, если они были запланированы раньше, а HTTP-запрос будет ждать своей очереди в фазе poll.
Даже внутри обработчика запроса все микротаски и process.nextTick попадают в свою очередь и выполняются после основной синхронной части. То есть сначала выполнится весь код в теле обработчика, а потом — всё, что было отложено.
Например:
const http = require('http');
http.createServer((req, res) => {
console.log('start');
process.nextTick(() => {
console.log('nextTick');
});
Promise.resolve().then(() => {
console.log('promise');
});
console.log('end');
res.end('ok');
}).listen(3000);
При запросе на сервер вывод будет таким:
start
end
nextTick
promise
Это означает, что микротаски внутри запроса тоже не “перебивают” его выполнение. Сначала идёт синхронный код, и только потом — очередь микротасок.
А что будет, если клиент пришёл с запросом, и сервер начал выполнять что-то тяжёлое? Что произойдет с остальными клиентами? Сейчас разберемся.
Потоковая обработка данных и блокировка Event Loop
Когда в Node.js приходит HTTP-запрос, объекты req и res представляют собой потоки (streams). Это означает, что данные приходят и отправляются по частям, а не загружаются и обрабатываются целиком. Такой подход позволяет экономно использовать память и избегать блокировки Event Loop.
Однако если внутри запроса выполнить тяжёлую синхронную операцию, это может полностью остановить обработку всех остальных запросов. Стандартно Node.js работает в одном потоке, и пока выполняется тяжёлая операция, Event Loop не может перейти к следующему событию.
Например, если создать такой сервер:
const http = require('http');
function heavySyncWork() {
const end = Date.now() + 5000;
while (Date.now() < end) {}
}
http.createServer((req, res) => {
if (req.url === '/block') {
heavySyncWork();
res.end('Done with blocking work');
} else {
res.end('Hello!');
}
}).listen(3000);
и отправить запрос на /block, сервер на пять секунд перестанет отвечать на любые другие входящие запросы. Даже если другой клиент обратится к /, он не получит ответ до тех пор, пока heavySyncWork не завершится. Все запросы обрабатываются в одном Event Loop, и пока он занят, очередь просто ждёт.
Существует и другой вариант блокировки — с использованием process.nextTick(). Этот механизм позволяет выполнять задачи перед переходом к следующей фазе Event Loop, но при неправильном использовании может привести к зависанию.
http.createServer((req, res) => {
if (req.url === '/tick') {
function infiniteTick() {
process.nextTick(infiniteTick);
}
infiniteTick();
res.end('Never reached');
} else {
res.end('Still alive');
}
}).listen(3000);
В этом примере функция infiniteTick никогда не позволяет Event Loop перейти к следующей фазе. Результат — первый запрос на /tick даже не вернет Never reached (потому что Event Loop застрял на микротасках), а дальше сервер полностью зависает.
Чтобы избежать подобных ситуаций, в Node.js в частности рекомендуется использовать потоковую обработку данных. Она позволяет обрабатывать большие объёмы информации без блокировки Event Loop и без необходимости загружать всё в память сразу. Пример — передача большого файла клиенту:
const fs = require('fs');
const http = require('http');
http.createServer((req, res) => {
const readStream = fs.createReadStream('./bigfile.txt');
readStream.pipe(res);
}).listen(3000);
Файл читается и отправляется по частям. Такой подход позволяет избежать задержек и обрабатывать другие запросы параллельно, даже если файл очень большой.
Почему важно ставить таймауты
Node.js позволяет держать соединение с клиентом открытым столько, сколько потребуется. Это удобно для медленных клиентов и для повторного использования соединений, но одновременно — риск для сервера.
Если клиент подключился, но не отправляет данные или делает это очень медленно, Node.js будет держать соединение открытым, занимая ресурсы. Без явных ограничений такие соединения могут висеть вечно.
Node.js по умолчанию использует поведение keep-alive, когда соединение после ответа не закрывается сразу, а остаётся открытым в ожидании новых запросов от клиента. Это экономит ресурсы на повторное соединение, но в условиях высокой нагрузки может стать проблемой.
Пример:
const http = require('http');
const server = http.createServer((req, res) => {
setTimeout(() => {
res.end('done');
}, 10000); // ответ через 10 секунд
});
server.listen(3000);
Если к такому серверу подключатся десятки клиентов, которые просто откроют соединение и не дождутся ответа, соединения останутся висеть. Каждый из них займёт часть ресурсов: файловый дескриптор, память, место в очереди. Со временем это может привести к отказу в обслуживании новых запросов.
Чтобы избежать этого, можно и нужно задавать таймауты:
server.setTimeout(5000); // закрыть соединение, если нет активности 5 секунд
req.setTimeout(3000); // клиент слишком долго не отправляет тело запроса
res.setTimeout(5000); // задержка при формировании ответа
Кроме того, можно отключить keep-alive, если сервер не рассчитан на повторное использование соединений:
res.setHeader('Connection', 'close');
А что если вообще не ставить таймауты?
В теории — соединение может висеть бесконечно. На практике его может закрыть:
- сам клиент (например, браузер);
- TCP-уровень операционной системы;
- прокси или балансировщик (например, nginx).
Но всё это — внешние факторы, на которые нельзя полагаться. Некоторые роутеры могут держать соединения открытыми 10 минут, другие — сбрасывать через 30 секунд. Если сервер под нагрузкой, даже 10–20 таких «висящих» соединений без таймаутов могут съесть ресурсы и мешать обслуживанию новых запросов.
Поэтому безопаснее выставлять таймауты явно — на уровне server, req, res и, при необходимости, использовать ограничения на стороне балансировщика.
Обработка ошибок на сервере
Если в обработчике HTTP-запроса в Node.js произойдёт необработанная ошибка, она может привести к падению всего процесса. Node.js не оборачивает callback http.createServer в try/catch — ожидается, что разработчик сам контролирует возможные сбои. В результате любое неперехваченное исключение завершит работу сервера.
Пример:
http.createServer((req, res) => {
if (req.url === '/crash') {
throw new Error('Something went wrong');
}
res.end('OK');
}).listen(3000);
При обращении к /crash процесс завершится с ошибкой. Чтобы этого избежать, стоит оборачивать обработчик запроса в try/catch:
http.createServer((req, res) => {
try {
if (req.url === '/crash') {
throw new Error('Something went wrong');
}
res.end('OK');
} catch (err) {
console.error('Request error:', err);
res.statusCode = 500;
res.end('Internal Server Error');
}
}).listen(3000);
Сложности возникают при работе с асинхронным кодом — если ошибка произойдёт внутри Promise или async-функции, она не будет перехвачена внешним try/catch. Чтобы корректно обработать такую ситуацию, нужно явно добавить .catch:
http.createServer((req, res) => {
(async () => {
if (req.url === '/crash') {
throw new Error('Async error');
}
res.end('OK');
})().catch(err => {
console.error('Async error:', err);
res.statusCode = 500;
res.end('Internal Server Error');
});
}).listen(3000);
В сложных проектах с множеством маршрутов удобно использовать фреймворки, которые предоставляют централизованную обработку ошибок. Но даже в простом сервере важно помнить, что один throw без catch способен остановить всё приложение.
Фреймворки для сервера
Многие фреймворки скрывают работу с http.createServer, но под капотом всё устроено так же. Express, например, просто оборачивает стандартный HTTP-сервер и выстраивает цепочку middleware, которая вызывается последовательно.
Асинхронные middleware в Express действительно работают с await, и если использовать промисы корректно, Event Loop не блокируется. Но это не магия — await просто приостанавливает выполнение текущей функции, пока не завершится промис. В это время Event Loop может обрабатывать другие события. Если же в middleware будет тяжёлая синхронная операция вроде while (true) {}, Event Loop всё равно будет заблокирован.
Пример:
app.get('/block', (req, res) => {
while (true) {} // сервер зависает
});
app.get('/async', async (req, res) => {
await new Promise(resolve => setTimeout(resolve, 1000));
res.send('OK');
});
Во втором случае сервер спокойно продолжает обслуживать другие запросы во время ожидания. В первом — замирает полностью.
NestJS работает поверх Express (или Fastify) и использует тот же принцип middleware и контроллеров, но добавляет уровни абстракции, инъекцию зависимостей и декларативную обработку ошибок. По умолчанию NestJS уже перехватывает исключения в контроллерах и может возвращать корректный статус 500 без падения сервера.
Важно понимать, что NestJS не делает Event Loop «волшебным». Если внутри контроллера происходит блокирующая операция, поведение будет таким же, как и в Express — ни один фреймворк не может обойти модель выполнения Node.js.
Фреймворки упрощают структуру кода, делают обработку ошибок более предсказуемой и помогают не забыть про важные детали. Но фундамент остаётся прежним: один Event Loop, один поток, и ответственность за производительность — на приложении.
Выводы
В этой части мы разобрались, как Node.js обрабатывает входящие HTTP-запросы и что стоит под капотом. Посмотрели, как http.createServer связан с TCP и Event Loop, и почему каждый запрос — это не мгновенное действие, а событие в общей очереди.
Разобрали, как потоки (streams) помогают обрабатывать данные без блокировки, и почему тяжёлые синхронные операции могут повесить сервер. Поговорили о важности таймаутов и том, что будет, если их не выставить. Затронули обработку ошибок и то, как один throw может остановить весь процесс. А в конце — посмотрели, как с этим справляются Express и NestJS, и почему фреймворки не отменяют фундаментальную модель выполнения Node.js.
Часть 5. Настоящая многопоточность.
Во всех предыдущих частях мы уже говорили о том, что Event Loop в Node.js работает в единственном основном потоке. При этом часть операций — например, чтение файлов — может выполняться в thread pool’е, специальном пуле потоков, куда Node.js отправляет тяжёлые задачи.
Но несмотря на это, весь наш JavaScript-код, а также ключевые операции вроде обработки запросов, выполняются строго в одном потоке. Именно поэтому Node.js и называют однопоточным — по крайней мере, с точки зрения приложения.
Однако в реальности у него всё же есть способы выйти за рамки одного потока. Сегодня как раз о них и поговорим.
Зачем нужна многопоточность в Node.js
Node.js изначально создавался для обработки множества одновременных I/O-запросов — например, сетевых или файловых. Тут он хорош: один поток, неблокирующий код, быстрые ответы. Но как только внутри этого потока появляется тяжёлая синхронная задача, всё — Event Loop стопорится, сервер замирает, пользователи ждут.
Чтобы как-то с этим жить, ещё с ранних версий Node.js в ядре был модуль child_process. С его помощью можно было запускать внешние команды и сторонние скрипты — например, shell-скрипт или python your_script.py. Однако общение с этими процессами было довольно ограниченным (stdin и stdout), и всё упиралось в строки и парсинг.
Потом появился метод fork, и он уже был заточен на запуск других Node.js-скриптов. Главное отличие — возможность устанавливать двустороннюю связь между родителем и потомком через IPC — межпроцессное взаимодействие. То есть можно передавать JavaScript-объекты с помощью process.send() и ловить их на стороне дочернего процесса. Это уже похоже на то, как хочется строить многопоточность: можно делегировать тяжёлую задачу во «второй процесс» и не блокировать основной поток.
Вот пример:
// main.js
const { fork } = require('child_process');
const worker = fork('./worker.js');
worker.send({ action: 'compute', value: 42 });
worker.on('message', (result) => {
console.log('Результат от воркера:', result);
});
// worker.js
process.on('message', (msg) => {
if (msg.action === 'compute') {
const res = сalculation(msg.value);
process.send(res);
}
});
function сalculation(num) {
return num * 2;
}
В этом примере основное приложение остаётся отзывчивым, а тяжёлая работа уходит в отдельный процесс. Однако и здесь всё приходилось делать вручную: запускать нужное количество воркеров, самому распределять задачи, следить, чтобы кто-то не умер, и при этом не забывать, что каждый процесс ест свою память. С ростом нагрузки всё это становилось болью, и разработчикам остро не хватало более высокого уровня абстракции.
Так и появился cluster — инструмент, который взял на себя менеджмент процессов.
Cluster
Модуль cluster стал первым официальным способом масштабировать серверное приложение в Node.js. Он использует child_process.fork() под капотом, но оборачивает его в более удобное API, снимая с разработчика головную боль по ручному менеджменту воркеров.
Главная фишка cluster — он позволяет запускать несколько процессов, которые слушают один и тот же порт. Это значит, что мы можем поднять сервер в каждом воркере, а Node.js сам распределит входящие запросы между ними.
Кроме того, cluster умеет:
- следить за состоянием воркеров;
- перезапускать упавшие процессы;
- управлять их количеством на лету.
Вот простой пример, как это выглядит:
const cluster = require('cluster');
const os = require('os');
const http = require('http');
if (cluster.isMaster) {
const cpuCount = os.cpus().length;
console.log(`Master запущен. Форкаем ${cpuCount} воркеров...`);
for (let i = 0; i < cpuCount; i++) {
cluster.fork();
}
cluster.on('exit', (worker) => {
console.log(`Воркер ${worker.process.pid} умер. Перезапускаем...`);
cluster.fork();
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end(`Ответ с воркера ${process.pid}\n`);
}).listen(3000);
console.log(`Воркер ${process.pid} слушает порт 3000`);
}
Каждый запущенный воркер — полноценный процесс со своим PID, но все они отвечают на одном и том же порту. Мастер-процесс не занимается обработкой запросов — он просто управляет рабочими и следит, чтобы всё было стабильно.
Однако у cluster есть и свои ограничения. Несмотря на все плюсы, он работает не с потоками, а с полноценными отдельными процессами, а это накладывает определённые ограничения на архитектуру и производительность.
Во-первых, у каждого воркера — своя изолированная память. Это значит, что если мы хотим, чтобы все воркеры использовали, скажем, общий кэш или доступ к общим данным — мы не сможем просто создать объект и расшарить его между ними. Придётся писать отдельный механизм обмена — например, через файл или базу данных. Это добавляет как сложность, так и задержки.
Во-вторых, вся коммуникация между мастер-процессом и воркерами идёт через сериализацию. Когда мы используем worker.send({ user }), объект превращается в сериализованную структуру, пересылается по каналу, а затем десериализуется на другой стороне. Это значит:
- нельзя передавать функции, ссылки на классы, замыкания и т.д.;
- есть накладные расходы на упаковку и распаковку данных;
- сложные или большие структуры могут передаваться с задержками.
И наконец, каждый воркер — это полноценный процесс, со своими ресурсами. Он ест память, грузит CPU и создаёт нагрузку на систему. Если мы запускаем по воркеру на каждое ядро — всё ок. Но если у нас появляются десятки или сотни таких воркеров (например, для обработки каждой задачи в отдельном процессе) — память может закончиться очень быстро. В отличие от потоков, процессы не делят heap, и каждое дублирование чего-то «общего» — это дополнительные байты в памяти.
Поэтому cluster идеально подходит для масштабирования HTTP-серверов по ядрам, но становится менее удобным, когда нужно:
- запускать множество параллельных задач;
- быстро обмениваться данными;
- экономно расходовать ресурсы внутри одного приложения.
Вот тут на сцену выходят worker_threads, которые решают эти проблемы, предлагая настоящую многопоточность внутри одного процесса.
Worker Threads
В отличие от cluster, который запускает отдельные процессы, worker_threads создают воркеров как потоки: у каждого своя стековая память, но общая куча. Это позволяет делить память между потоками, избегать сериализации при передаче данных и в целом работать быстрее и экономнее, особенно при большом количестве параллельных задач.
Каждый воркер получает собственный Event Loop, может выполнять JavaScript-код независимо и возвращать результат обратно в основной поток. Это особенно полезно в случае тяжёлых вычислений, вроде парсинга, шифрования или генерации отчётов, которые в однопоточном режиме блокировали бы всё приложение.
Вот пример, как это работает:
// main.js
const { Worker } = require('worker_threads');
function runWorker(data) {
return new Promise((resolve, reject) => {
const worker = new Worker('./worker.js', { workerData: data });
worker.on('message', resolve);
worker.on('error', reject);
worker.on('exit', (code) => {
if (code !== 0) reject(new Error(`Worker stopped with code ${code}`));
});
});
}
runWorker(42).then((result) => {
console.log('Результат от потока:', result);
});
// worker.js
const { parentPort, workerData } = require('worker_threads');
function heavyComputation(input) {
const start = Date.now();
while (Date.now() - start < 2000) {}
return input * 2;
}
const result = heavyComputation(workerData);
parentPort.postMessage(result);
В этом примере главный поток продолжает работать, а вычисления выполняются в фоне. Потоки запускаются быстро, используют меньше памяти, чем процессы, и позволяют эффективно распараллеливать задачи. Дополнительно можно использовать SharedArrayBuffer, если нужно совместно использовать память между потоками.
Несмотря на все плюсы, worker_threads не подходят для масштабирования HTTP-серверов — каждый поток не может слушать один и тот же порт. Поэтому в задачах, связанных с обработкой HTTP-запросов и распределением трафика, по-прежнему предпочтительнее использовать cluster.
Как выбрать
На сегодняшний день в Node.js есть несколько способов распараллеливания работы: child_process, cluster и worker_threads. Каждый из них решает свою задачу, и выбирать стоит не по принципу «что моднее», а в зависимости от реальных потребностей.
Если нужно просто запустить внешнюю программу, вроде ffmpeg или python-скрипта, подойдёт child_process.spawn() или exec(). Если важно запустить отдельный Node.js-скрипт и наладить простое общение между процессами — поможет fork().
Когда стоит задача масштабировать сетевой сервер и использовать все ядра CPU, удобнее всего использовать cluster: он автоматически распределяет входящие соединения между воркерами и позволяет обрабатывать больше трафика без лишней боли. Но при этом каждый воркер — полноценный процесс, с отдельной памятью и своими ресурсными затратами.
А вот если речь идёт о тяжёлых вычислениях, которые могут блокировать Event Loop, но запускать отдельный процесс ради этого — слишком жирно, разумнее использовать worker_threads. Они запускаются быстрее, потребляют меньше памяти и позволяют эффективно использовать многопоточность внутри одного процесса.
Но самое важное — все эти инструменты скорей всего не нужны, если приложение работает с I/O, базами данных или API и не упирается в CPU. Node.js прекрасно справляется с асинхронными задачами в однопоточном режиме, и добавление потоков или процессов «просто потому что» — чаще вред, чем польза.
Выводы
Мы рассмотрели, как Node.js эволюционировал от использования отдельных процессов через child_process и fork до более удобного инструмента — cluster, а затем перешли к настоящей многопоточности с помощью worker_threads.
В следующей части мы углубимся в тему профилирования и замеров, чтобы знать наверняка, когда такие решения необходимы, а когда — избыточны.
Часть 6. Профилировать и замерять.
Мы уже разобрались, как устроен Event Loop в Node.js, чем он отличается от браузерного, почему Node.js нельзя считать строго однопоточной средой и как всё-таки добиться параллельности при выполнении кода. В этой — финальной — части хочется поговорить о том, как понять, что с приложением что-то не так, и что с этим делать.
Иногда кажется, что «всё нормально»: код работает, сервер отвечает, ошибок нет. Но в реальности Event Loop может не справляться, запросы начинают тормозить, а пользователи — жаловаться. Эти проблемы не всегда очевидны, особенно если не смотреть вглубь и не измерять, где именно приложение теряет время.
Что можно замерять и зачем это делать
Node.js-приложение — это большое количество разных компонентов: Event Loop, очередь микрозадач, обработка файлов, запросы к сети, сборщик мусора и модули C++. Каждый из этих участков может стать узким местом. А иногда всё кажется быстрым — пока не запустить нагрузочный тест и не увидеть, как Event Loop захлёбывается от работы.
Что вообще можно профилировать:
- Время выполнения кода. Простая, но критичная метрика. Иногда достаточно тяжёлой регулярки или цикла внутри промиса, чтобы всё начало лагать.
- Задержки Event Loop. Даже если код асинхронный, Event Loop может не успевать обрабатывать задачи, потому что в какой-то момент его что-то заблокировало.
- Нагрузка на CPU. В Node.js любые синхронные вычисления выполняются в основном потоке. Это значит, что один тяжёлый
forможет замедлить все остальные запросы. - Операции с памятью. Если приложение начинает потреблять всё больше памяти — можно столкнуться с утечками и неожиданным поведением сборщика мусора.
- Асинхронные цепочки. Иногда промисы или
setTimeoutвызываются слишком часто, или навешано слишком много слушателей. - Зависшие ресурсы. Таймеры, сокеты и стримы, которые “забыли закрыть”, мешают завершению процесса и грузят Event Loop впустую.
Однако здесь мы сфокусируемся на двух ключевых направлениях, которые влияют на производительность уже на раннем этапе:
- Время выполнения кода (CPU-bound задачи)
- Состояние и здоровье Event Loop
Мы посмотрим, как это можно замерить встроенными средствами Node.js и какими продвинутыми инструментами воспользоваться для профилирования.
Базовые метрики в Node.js
Допустим, у нас есть кусок кода, который почему-то работает подозрительно долго. Вроде бы всё асинхронно, но API отвечает с задержкой, а иногда сервер будто на мгновение замирает. Чтобы проверить, где именно уходит время, начнём с самого простого — замеров времени выполнения.
Возьмём для примера странный код, в котором используется “безобидная” регулярка:
const text = 'a'.repeat(20) + '!';
const pattern = /(a+)+$/;
const start = Date.now();
pattern.test(text);
console.log(`Время выполнения: ${Date.now() - start} мс`);
На коротких строках всё отрабатывает мгновенно. Но если подставить определённую последовательность, время выполнения может вырасти в десятки и даже сотни миллисекунд. Это классический пример плохой регулярки, про которые мы уже говорили в третьей части, и Date.now() позволяет заметить лаг. Однако есть нюанс: Date.now() зависит от системных часов, а они могут скакать — например, если пользователь меняет время вручную. В условиях профилирования это создаёт ненадёжность: миллисекунды могут “потеряться” или “добавиться” не по вине нашего кода.
Вместо Date.now() можно использовать модуль perf_hooks, встроенный в Node.js. Он даёт более стабильные и точные средства измерения времени. В частности, performance.now() показывает, сколько времени прошло с момента запуска процесса — идеально для замеров внутри одного выполнения.
Перепишем наш пример с perf_hooks:
const { performance } = require('perf_hooks');
const text = 'a'.repeat(20) + '!';
const pattern = /(a+)+$/;
const start = performance.now();
pattern.test(text);
const end = performance.now();
console.log(`Время выполнения: ${(end - start).toFixed(3)} мс`);
Этот подход надёжнее: он не зависит от системного времени и даёт высокую точность. Помимо performance.now(), в perf_hooks есть и более продвинутые средства — например, performance.mark() и performance.measure(), которые позволяют расставлять метки в коде и потом измерять расстояние между ними, даже асинхронно. Это удобно, если хочется понять, сколько времени занимает какой-то этап обработки, не засоряя код ручными расчётами.
И, раз уж мы говорим про Event Loop, нельзя обойти стороной monitorEventLoopDelay() — инструмент, который показывает, насколько сильно цикл событий захлёбывается от нагрузки.
Вот пример, в котором Event Loop явно страдает:
const { monitorEventLoopDelay } = require('perf_hooks');
const h = monitorEventLoopDelay({ resolution: 10 });
h.enable();
setTimeout(() => {
const start = Date.now();
// Симулируем блокировку Event Loop
const now = Date.now();
while (Date.now() - now < 300) {}
const end = Date.now();
console.log(`Синхронная блокировка заняла: ${end - start} мс`);
setTimeout(() => {
h.disable();
console.log(`Event Loop delay (mean): ${(h.mean / 1e6).toFixed(2)} мс`);
console.log(`Event Loop delay (max): ${(h.max / 1e6).toFixed(2)} мс`);
}, 100);
}, 100);
Результат запуска может быть таким:
Синхронная блокировка заняла: 300 мс
Event Loop delay (mean): 26.85 мс
Event Loop delay (max): 311.43 мс
В этом примере мы намеренно блокируем Event Loop на 300 миллисекунд. Замеры покажут, что max-задержка резко возросла, хотя средняя (mean) может остаться ниже — ведь всё остальное время Event Loop дышал нормально. Это хороший способ заметить единичные “затыки”, которые иначе прошли бы незамеченными.
Однако у performance.now() и monitorEventLoopDelay() есть ограничения: они измеряют время в миллисекундах (пусть и с высокой точностью), и иногда хочется ещё более тонкой настройки. В таких случаях на помощь приходит process.hrtime.
process.hrtime возвращает время с наносекундной точностью. Его удобно использовать для вычисления относительных замеров, особенно в синхронном коде:
const start = process.hrtime.bigint();
pattern.test(text);
const end = process.hrtime.bigint();
console.log(`Время выполнения: ${(end - start) / BigInt(1e6)} мс`);
В отличие от performance.now(), здесь результат нужно делить на 1e6, чтобы получить миллисекунды — зато точность действительно выше, а влияние фоновых процессов минимально. Этот подход особенно ценен, если нужно профилировать критичный участок кода и хочется, чтобы замеры были максимально стабильными между запусками.
При этом process.hrtime чуть менее удобен в использовании и не так хорошо интегрируется с остальными средствами perf_hooks — например, с performance.measure(). Поэтому на практике performance.now() чаще используется для повседневных задач, а hrtime — когда нужна высочайшая точность.
Однако, все эти замеры — это скорее ручная работа. Да, она полезна для точечной диагностики, но когда нужно понять общую картину, следить за “здоровьем” Event Loop или искать узкие места в целом приложении, одного console.log уже может не хватить.
Инструменты для анализа и профилирования
В этом блоке разберём, как можно анализировать поведение кода с помощью настоящих профилировщиков — от встроенных инструментов до удобных внешних тулов.
Для экспериментов здесь используется вот этот демо-репозиторий: naugtur/node-example-flamegraph
Он специально создан для демонстрации “тормозов” Node.js-приложения. С помощью переменной HOW_OBVIOUS_THE_FLAME_GRAPH_SHOULD_BE_ON_SCALE_1_TO_100 можно управлять уровнем нагрузки: чем выше значение, тем заметнее проблемы на профиле.
node --prof и node --prof-process
Начнём с самого низкоуровневого инструмента, который есть в самой Node.js. Это встроенный профилировщик V8, который снимает сэмплы выполнения и сохраняет их в текстовый файл.
Чтобы запустить его, нужно использовать две команды:
node --prof app.js
После завершения работы создастся файл, похожий на isolate-0x*.log (например, у меня isolate-0x158008000-59638-v8.log). Его нужно обработать:
node --prof-process isolate-0x158008000-59638-v8.log > processed.txt
В результате получится отчёт, где будет видно, какие функции занимали больше всего времени, насколько часто они вызывались и как выглядел вызов CPU.
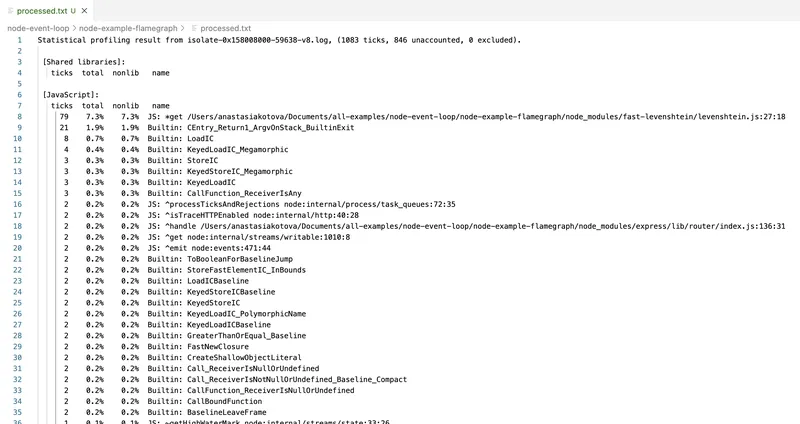
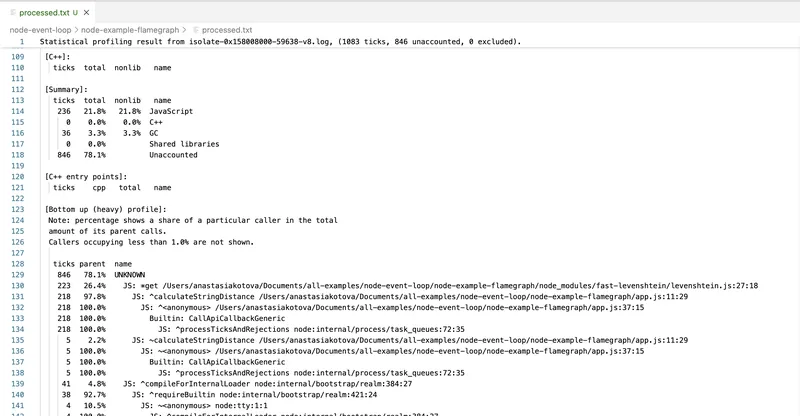
Этот инструмент использует внутренние средства самого движка V8 и показывает сырой профиль исполнения, включая даже вызовы на уровне C++. Однако, у него есть и минусы.
Во-первых, интерфейс практически нечитаемый. Все имена функций перемешаны с внутренними вызовами. Во-вторых, нет никаких визуализаций — только текст. Чтобы разобраться в профиле, нужно обладать недюжинной силой воли, или использовать обёртки, вроде 0x.
0x: быстрый flamegraph без боли
0x — это обёртка над --prof, которая делает всё то же самое, но с визуализацией. Он запускает код, собирает профиль и автоматически генерирует HTML-файл с flamegraph.
Пример запуска:
0x app.js
После выполнения мы получаем flamegraph.html, где можно визуально увидеть, какая функция сколько времени провела на CPU. Ширина каждого блока пропорциональна времени — чем шире, тем дольше выполнялся код.
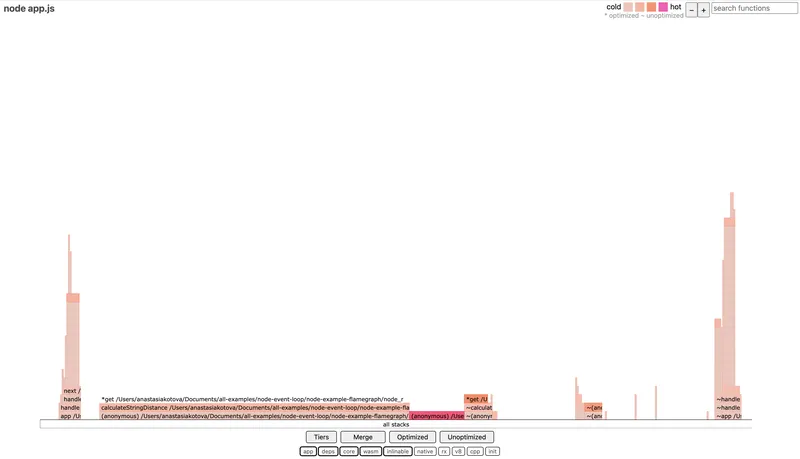
С 0x удобно анализировать CPU-bound участки — например, тяжёлые циклы, вычисления, проблемные регулярки. Он не показывает async-зависимости, зато идеально подходит, если нужно быстро понять, где именно “горит” процессор.
clinic: общее обследование
clinic — это набор утилит, который включает clinic flame, clinic doctor и clinic bubbleprof. В данном случае нас интересует clinic flame — он делает почти то же самое, что и 0x, но с чуть более детальной визуализацией и удобной обёрткой.
Команда для запуска:
clinic flame -- node app.js
По завершении откроется HTML-отчёт с flamegraph. Можно кликать по функциям, смотреть стеки вызовов, приближать участки и сохранять вывод.
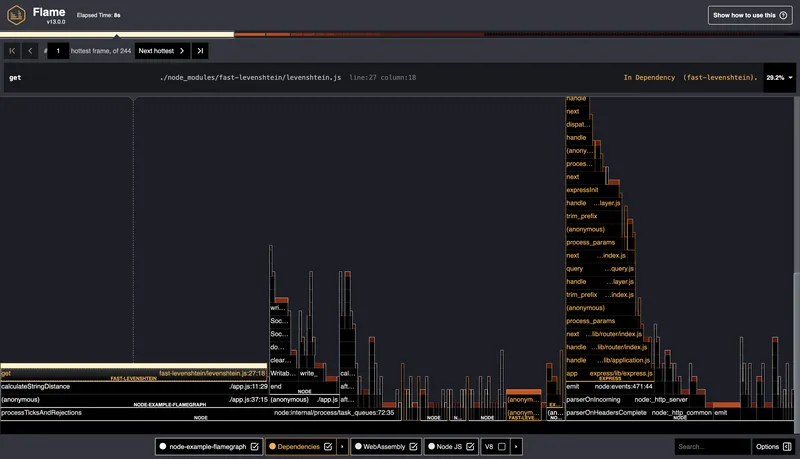
Отличие от 0x — чуть больше информации в визуализации и совместимость с остальными инструментами clinic.
Когда не совсем понятно, что именно тормозит — CPU, Event Loop, или что-то с памятью — удобно начать с более общей диагностики. Для этого есть clinic doctor. Он собирает несколько типов метрик одновременно: нагрузку на процессор, задержки Event Loop, использование памяти, частоту входящих запросов и т. д.
Команда:
clinic doctor -- node app.js
После запуска нужно немного поработать с приложением (например, открыть страницу сервера в браузере или сделать запросы через curl), а затем остановить процесс — отчёт откроется автоматически.
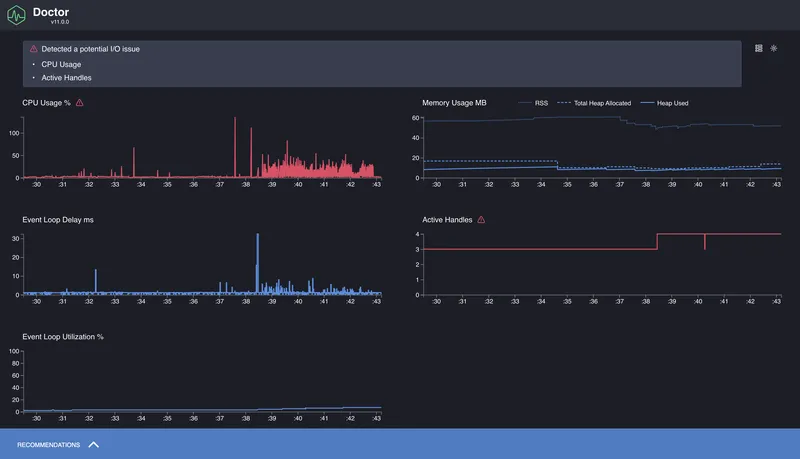
На выходе мы получим общую картину: насколько равномерна нагрузка, есть ли задержки Event Loop, как ведёт себя память.
Что такое flamegraph и как его читать
Мы посмотрели, как использовать 0x и clinic flame, и получили результат в виде графа, где всё подсвечено и разложено по уровням. На первый взгляд это может выглядеть как просто красивый отчёт, но на самом деле flamegraph — мощный инструмент анализа производительности.
Flamegraph — это визуализация профиля выполнения кода. Каждая функция в стеке вызовов отображается как прямоугольник. Ширина блока показывает, сколько времени эта функция провела на CPU. Чем шире блок — тем больше он «съел» времени. Все блоки укладываются в общую ширину графа, которая соответствует полной загрузке CPU за время профилирования.
Граф «растёт» снизу вверх. Нижние блоки — это то, с чего начинался стек вызовов. Верхние — то, что вызывалось внутри. Если на нижнем уровне появляется особенно широкая полоска, это верный признак узкого места: функция выполняется часто и/или долго и блокирует другие действия.
Важно: flamegraph показывает только то, что происходило на CPU. Асинхронные задержки, ожидания, промисы, таймеры — всё, что не занимало CPU, — в flamegraph не отразится. Это делает его идеальным инструментом для поиска синхронных затыков, но неполным — и именно поэтому clinic включает ещё и другие инструменты, вроде doctor и bubbleprof.
Сами flamegraph-отчёты интерактивны: можно увеличивать, искать по названию функций, просматривать стек вызовов. Это особенно полезно при анализе больших проектов, где стек может уходить в десятки уровней глубины.
Выводы
В этой части мы разобрались, как подступиться к профилированию Node.js-приложений: что можно замерять, какие инструменты использовать и как интерпретировать полученные результаты. Мы посмотрели, как замерять время выполнения с помощью performance.now() и process.hrtime, как отследить задержки Event Loop через monitorEventLoopDelay(), и как использовать профилировщики — от встроенного --prof до 0x и clinic.
Формат flamegraph оказался особенно удобным для выявления синхронных узких мест: тяжёлых регулярок, блокирующих циклов и всего, что занимает слишком много CPU. А clinic doctor дал нам более широкую картину: общее поведение Event Loop, нагрузку, память, частоту запросов.
Это только основа. За ней — целый пласт тем, в которые можно углубляться дальше: профилирование в продакшене, нагрузочное тестирование, работа с памятью и её утечками, async performance.