От кода до пикселей: как работает рендеринг
Часть 1. Браузерные движки.
Введение
Интерфейс — это не только логика на JavaScript. В конечном итоге всё сводится к тому, что именно и как пользователь видит на экране. Это может быть сложная форма с кучей состояний и валидаций, а может — падающие снежинки в интерфейсе под Новый год.
HTML, CSS, вёрстка: не все интерфейс-разработчики любят глубоко погружаться в эти темы. А мне, как обычно, хочется залезть в самые кишочки происходящего. Поэтому в этом исследовании мы будем разбираться, как именно работает рендеринг — что происходит между моментом, когда браузер получил URL страницы и загрузил HTML, и моментом, когда мы увидели готовую страницу. И начнём с архитектуры браузера и того, из каких частей он вообще состоит.
Многопроцессная архитектура браузера на примере Chromium
В предыдущих исследованиях мы много говорили про V8 — движок, который выполняет JavaScript и используется не только в Node.js, но и во многих браузерах. Но браузер — это гораздо более сложная система, и V8 в ней всего лишь один из компонентов.
В сегодняшнем исследовании я буду опираться на Chromium — open-source проект, на базе которого работают Chrome, Edge, Opera и другие браузеры.
Одна из ключевых особенностей Chromium — многопроцессная архитектура. Вместо одного процесса браузер разбит на несколько независимых процессов, каждый из которых отвечает за свою задачу. Это сделано в первую очередь ради безопасности и устойчивости: если что-то сломалось в одном процессе, весь браузер не упадёт.
Процесс — это изолированный экземпляр программы. У процесса есть собственное адресное пространство памяти, свои ресурсы (heap, стек, файловые дескрипторы) и ограничения доступа. Процессы не могут напрямую читать или писать память друг друга — для этого нужны специальные механизмы (IPC).
Главный процесс называется browser process. Он отвечает за пользовательский интерфейс браузера, управление вкладками, окнами и за координацию остальных процессов.
Отдельно существуют дочерние renderer processes — процессы, которые занимаются отображением веб-контента. Именно в них происходит разбор HTML, выполнение JavaScript и, в конечном итоге, рендеринг страницы. Каждый такой процесс использует движок Blink для интерпретации и отображения контента.
Внутри процесса рендеринга находятся специальные объекты RenderFrame, которые соответствуют фреймам с документами — основному документу страницы и iframe.
Обычно новая вкладка или окно запускается в новом процессе рендеринга. Browser process создаёт процесс и говорит ему создать один RenderFrame. Внутри страницы при этом могут появляться iframe — иногда в том же процессе, а иногда в других.
И тут возникает важный вопрос: сколько вообще процессов рендеринга создаётся?
С точки зрения безопасности идеальный вариант — отдельный процесс на каждый сайт. Это называется изоляцией сайтов. Сайт здесь — это протокол URL + регистрируемый домен + один уровень поддомена. Например, mail.example.com и chat.example.com считаются одним сайтом, а example.com и example2.com — разными.
Но в реальности всё не так просто. Если у пользователя открыто очень много вкладок или устройство слабое, браузеру может быть слишком дорого держать по процессу на каждый сайт. В таких случаях один процесс рендеринга может обслуживать несколько вкладок или iframe с разных сайтов. Поэтому между вкладками, iframe и процессами нет жёсткого соответствия «один к одному».
Иногда браузер сознательно переиспользует процесс. Например, если страница через window.open открывает новое окно того же источника, браузер может оставить его в том же процессе.
Так как renderer работает отдельно от browser process, Chromium может жёстко ограничивать его права с помощью sandbox. Рендерер не может напрямую ходить в сеть, работать с файловой системой или получать доступ к устройствам ввода — всё это делается через специальные сервисы браузера. Это сильно снижает потенциальный ущерб, если процесс рендеринга будет скомпрометирован.
Помимо browser и renderer процессов, Chromium выносит в отдельные процессы и другие подсистемы — например, GPU, сетевой стек или хранилище данных. При этом вся сетевая коммуникация контролируется browser process, чтобы централизованно управлять cookies, кэшем и количеством соединений.
Движок для рендеринга Blink
Blink — это движок рендеринга, используемый в Chromium. Именно он отвечает за всё, что связано с отображением контента во вкладке браузера.
В его обязанности входит:
- реализация веб-стандартов (HTML, CSS, DOM);
- встраивание V8 и запуск JavaScript;
- загрузка ресурсов через сетевой стек;
- построение DOM-дерева;
- расчёт стилей и layout;
- взаимодействие с Chrome Compositor и отрисовка графики.
Процесс рендеринга — это не один поток. В Blink есть основной поток, несколько рабочих потоков и несколько внутренних служебных потоков. При этом почти всё важное происходит именно в основном потоке: выполнение JavaScript, работа с DOM, расчёт стилей и layout.
Поток (thread) — это единица выполнения внутри процесса. Несколько потоков разделяют память и ресурсы одного процесса, но выполняются параллельно. Создавать потоки дешевле, чем процессы, но ошибки в одном потоке могут повлиять на весь процесс.
Blink исторически оптимизирован под такую преимущественно однопоточную модель. Рабочие потоки используются для Web Workers, Service Workers и Worklets. Дополнительные внутренние потоки могут заниматься аудио, базами данных, сборкой мусора и другими задачами. Взаимодействие между потоками происходит через передачу сообщений.
Теперь немного про внутренние сущности Blink.
- Page почти соответствует вкладке браузера.
- Frame — это фрейм страницы: основной документ или iframe.
- DOMWindow — это объект
windowв JavaScript. - Document — это
window.document.
Связи между ними выглядят так:
- один процесс рендеринга может содержать несколько Page;
- одна Page может содержать несколько Frame;
- у каждого Frame в конкретный момент времени есть ровно один DOMWindow и один Document.
При навигации Frame может переиспользоваться, но DOMWindow и Document при этом создаются заново. Например, после выполнения кода iframe.contentWindow.location.href = "https://example.com" для существующего на странице iframe, создаётся новый Document и новый window, но сам объект Frame может остаться тем же.
Изоляция сайтов добавляет ещё один уровень сложности. Если страница содержит межсайтовый iframe, разные части страницы могут обслуживаться разными процессами рендеринга.
Например код на сайте https://example.com:
<body>
<iframe src="https://example2.com"></iframe>
</body>
В таком случае основной фрейм и iframe могут находиться в разных процессах, а обмен данными между ними происходит через browser process.
Взаимодействие с V8
В нашем исследовании про V8 мы уже разбирали взаимодействие Blink и V8, но здесь тоже важно повторить это.
Чтобы понять этот механизм, важно разобраться в трёх понятиях: изолят, контекст и мир. Они описывают разные уровни изоляции JavaScript-кода и отвечают на разные вопросы.
Изолят (Isolate) — это изолированная среда выполнения JavaScript внутри V8.
Проще всего думать о нём как об отдельной JS-машине со своей памятью и сборщиком мусора. В Chromium изолят жёстко привязан к потоку: у основного потока есть свой изолят, и у каждого worker'а — свой. Это означает, что JavaScript из разных потоков никогда не делит память напрямую.
Контекст (Context) — это конкретный контекст выполнения JavaScript, связанный с глобальным объектом.
Для обычной страницы это объект window. У каждого Frame есть свой window, а значит — свой контекст. При навигации контекст пересоздаётся: появляется новый window, новые глобальные переменные и новый JavaScript-окружение, даже если сам Frame при этом остаётся тем же.
Мир (World) — это логическая «песочница» для JavaScript-кода.
Эта концепция не существует в веб-стандартах и используется браузером для изоляции разных источников JavaScript. Самый наглядный пример — расширения браузера. Скрипты страницы и скрипты расширений должны работать с одним и тем же DOM, но при этом не иметь доступа к JavaScript-объектам друг друга. Для этого браузер создаёт несколько миров: основной мир страницы и отдельные изолированные миры для каждого из расширений. Важно, что DOM-дерево при этом общее — оно реализовано на стороне C++ в Blink. А вот JavaScript-объекты, через которые этот DOM доступен, разные для каждого мира.
Если собрать всё вместе, получается следующая картина:
- в одном потоке есть один изолят;
- внутри него могут существовать несколько фреймов;
- у каждого фрейма может быть несколько миров;
- и для каждой пары «фрейм + мир» создаётся свой JavaScript-контекст (то есть свой
window).
Thread
└── Isolate
└── Frame #1
│ ├── World #1 (страница)
│ │ └── Context (window)
│ ├── World #2 (расширение A)
│ │ └── Context (window)
│ └── World #3 (расширение B)
│ └── Context (window)
└── Frame #2
├── World #4 (страница)
│ └── Context (window)
└── World #5 (расширение C)
└── Context (window)
В worker'ах всё проще: там всегда один поток, один изолят, один мир и один контекст.
Эта многоуровневая модель нужна браузеру, чтобы одновременно обеспечивать безопасность, изоляцию и возможность разным частям системы работать с одним и тем же DOM, не ломая друг другу окружение.
От момента, когда HTML попадает в Blink, до появления пикселей на экране проходит длинный путь. Этот путь состоит из нескольких этапов — и именно их мы будем разбирать в следующей части.
Часть 2. Конвейер рендеринга.
В первой части мы разобрали, как работает браузер Chromium на уровне процессов и потоков. Теперь пришло время проследить полный путь от HTML, CSS и JavaScript до конкретных пикселей на экране. Этот путь называется конвейером рендеринга.
Начало и конец конвейера
Контент — это общий термин в Chromium для всего кода внутри веб-страницы или интерфейса веб-приложения. Он не включает в себя UI самого браузера, например адресную строку или элементы навигации. Основными строительными блоками контента являются:
- текст,
- изображения,
- HTML — разметка, окружающая текст,
- CSS — стили, определяющие способ отображения разметки,
- JavaScript — скрипты, которые могут динамически изменять всё вышеперечисленное.
Настоящая веб-страница представляет собой набор HTML, CSS и JavaScript-файлов, передаваемых по сети в виде обычного текста. Здесь нет этапов компиляции или упаковки, как это бывает на других программных платформах: исходный код страницы является прямым входом для системы рендеринга.
На другом конце конвейера браузеру необходимо вывести пиксели на экран, используя графические библиотеки операционной системы. Внутри Chromium ключевую роль играет библиотека Skia — именно она отвечает за отрисовку примитивов, текста, изображений и эффектов. Skia можно рассматривать как универсальный графический движок, абстрагирующий работу с конкретным «железом». На этапе raster браузер формирует команды рисования в терминах Skia, а затем транслирует их в вызовы низкоуровневых графических API, доступных на конкретной платформе.
В зависимости от системы и конфигурации Chromium может использовать разные бэкенды. Чтобы посмотреть, с каким именно графическим стеком работает браузер, можно открыть служебную страницу chrome://gpu. На ней отображается таблица с технической информацией, например, у меня она выглядит следующим образом:

Здесь видно, что основным 2D-бэкендом является Skia (поле 2D graphics backend), а в качестве графического движка используется связка Graphite, Dawn и Metal (поле Skia Backend). Это означает, что все операции рисования сначала проходят через Skia, затем обрабатываются новым рендер-ядром Graphite, переводятся через слой WebGPU-инфраструктуры Dawn и в итоге выполняются с помощью нативного API Apple — Metal. Параллельно браузер использует библиотеку ANGLE, которая транслирует вызовы OpenGL ES в Metal, позволяя Chromium сохранять единый графический интерфейс для разных платформ (поле Display type). Также из таблицы видно, что GPU работает в отдельном изолированном процессе, что повышает стабильность и безопасность (поля In-process GPU и Sandboxed), а фактический рендерер представляет собой Metal-реализацию под Apple M3 (поле GL_RENDERER).
Таким образом, Chromium не привязан к одному графическому API. Skia выступает в роли промежуточного слоя, а выбор конкретного бэкенда происходит динамически, исходя из платформы, драйверов и возможностей устройства. Это позволяет браузеру сохранять единый конвейер рендеринга и при этом эффективно использовать графическое ускорение в самых разных средах.
Основные стадии конвейера
Цель рендеринга можно сформулировать так: преобразовать HTML, CSS и JavaScript в корректные вызовы графической платформы для отображения пикселей. Однако при описании конвейера важно учитывать и вторую задачу: браузеру необходимы промежуточные структуры данных для эффективного обновления интерфейса и обработки запросов со стороны JavaScript и других подсистем.
Поэтому внутри Chromium конвейер рендеринга реализован как последовательность этапов, каждый из которых строит собственные структуры данных и подготавливает информацию для следующего шага. Важно понимать, что браузер не «перерисовывает страницу целиком» при каждом изменении. Он стремится переиспользовать уже вычисленные данные и обновлять только то, что действительно изменилось. Современная архитектура этого процесса описывается в рамках подхода RenderingNG.
В RenderingNG каждый кадр формируется в несколько этапов, которые условно делятся на три группы: подготовку данных на основном потоке (main thread), работу композитного потока (compositor thread) и финальный вывод через GPU (viz process). Внутри этих групп находятся конкретные стадии, выполняемые в строго определённом порядке. При этом не каждый кадр обязан проходить все этапы полностью: если изменения затрагивают только визуальные эффекты или прокрутку, браузер может обойтись без перерасчёта геометрии и повторной отрисовки контента.
Все начинается с парсинга HTML. Браузер анализирует текст документа, восстанавливает вложенность тегов и строит DOM — древовидную структуру, отражающую логическую организацию страницы.
Затем на стадии animate обновляются анимации, переходы и другие эффекты, зависящие от времени. Здесь формируются специальные структуры данных, описывающие прозрачность, трансформации, обрезку и другие визуальные свойства элементов. Эти данные позволяют изменять внешний вид элементов без полного пересчёта страницы.
После этого выполняется обработка стилей. Браузер вычисляет итоговые значения CSS-свойств для каждого элемента, учитывая каскад, наследование и специфичность.
Следующим этапом является layout — вычисление геометрии страницы. На этой стадии определяется размер и положение всех элементов, формируется дерево фрагментов, описывающее будущий макет. Это один из самых ресурсоёмких этапов, так как изменение одного элемента может повлиять на множество других.
На стадии pre-paint браузер обновляет визуальные структуры и определяет, какие части изображения больше нельзя переиспользовать. Это позволяет точно вычислить области, требующие перерисовки.
Далее следует стадия scroll, отвечающая за обновление прокрутки. Вместо пересчёта всей страницы браузер изменяет смещение области просмотра, используя уже существующие структуры данных.
На стадии paint формируется display list — список команд, описывающих, что и в каком порядке должно быть нарисовано. Этот список не привязан к конкретному графическому API и служит промежуточным представлением между логикой страницы и реальной отрисовкой.
После этого данные передаются с основного потока на композитный — этап commit. Он отделяет подготовку данных от визуального отображения, позволяя основному потоку продолжать выполнение JavaScript.
На стадии layerize сцена разбивается на композитные слои. Эти слои могут перемещаться и анимироваться независимо, однако их количество ограничивается соображениями производительности.
Далее следует растрирование, в ходе которого команды из display list преобразуются в текстурные тайлы, используемые GPU.
На стадии activate формируется compositor frame — описание структуры будущего кадра.
На этапе aggregate в viz-процессе объединяются кадры от разных источников: вкладок, интерфейса браузера и встроенных фреймов.
Финальной стадией является draw — непосредственная отрисовка кадра GPU и вывод изображения на экран.
По итогу пайплайн рендеринга в Chromium (RenderingNG) выглядит так:
1. **Парсинг**
→ парсинг HTML и CSS
→ построение DOM и таблиц стилей
2. **Animate**
→ обновление анимаций и временных эффектов
3. **Style**
→ применение CSS и вычисление итоговых стилей
4. **Layout**
→ расчёт размеров и позиций элементов
5. **Pre-paint**
→ подготовка к отрисовке, обновление визуальных состояний
6. **Scroll**
→ обработка прокрутки и смещения контента
7. **Paint**
→ формирование команд отрисовки
8. **Commit**
→ передача данных с main thread на compositor
9. **Layerize**
→ разбиение сцены на слои
10. **Raster / Decode / Paint Worklets**
→ растрирование, декодирование изображений, генерация текстур
11. **Activate**
→ сборка кадра для отображения
12. **Aggregate**
→ объединение кадров от разных источников
13. **Draw**
→ отрисовка через GPU
CPU и GPU задачи в Chromium
В современном конвейере рендеринга в Chromium чётко прослеживается граница между задачами CPU и GPU. Все этапы, связанные с анализом структуры страницы — парсинг, построение DOM, вычисление стилей, layout и формирование инструкций paint — выполняются на стороне CPU. Эти задачи требуют сложной логики и интерпретации спецификаций, что пока эффективнее реализуется на процессоре.
В то же время растеризация и финальный вывод выполняются на GPU. Графический процессор отвечает за преобразование команд рисования в пиксели, применение шейдеров, декодирование изображений и работу с нативными графическими API, такими как Metal, Vulkan или DirectX. Такое разделение позволяет CPU сосредоточиться на логике страницы, а GPU — на параллельной обработке графики. Перенос части compositing-операций в отдельные потоки дополнительно снижает нагрузку на основной поток и повышает отзывчивость интерфейса.
Часть 3. Стадии основного потока.
Парсинг
Когда HTML-документ начинает загружаться, Blink запускает потоковый парсинг входного байтового потока. Парсер работает инкрементально: он обрабатывает документ по мере поступления данных из сети, что позволяет начинать рендеринг ещё до полной загрузки страницы.
Входной поток разбивается на токены в соответствии со спецификацией HTML5. На их основе Chromium строит DOM-дерево, применяя правила построения документа, включая обработку некорректного HTML.
Параллельно с этим браузер парсит CSS и формирует на его основе CSSOM — CSS Object Model. Это дерево правил, оптимизированное для эффективного сопоставления стилей с элементами DOM.
Важная особенность парсера Chromium — спекулятивный preload scanner, работающий параллельно основному парсеру. Он просматривает HTML «на опережение», находит ссылки на внешние ресурсы (скрипты, стили, изображения) и инициирует их загрузку заранее, что заметно ускоряет общее время загрузки страницы.
Animate
После парсинга и построения DOM, когда приходит время обновить отображение, Chromium запускает пайплайн формирования кадра. Первый значимый этап в нём — фаза animate.
Вычисления на этом этапе могут выполняться как в основном потоке, так и в композитном, о чём мы подробнее поговорим позже.
В animate вызываются функции, зарегистрированные через requestAnimationFrame, так как их результат должен быть готов до начала layout. Обычно это изменения DOM или стилей.
Также в этой фазе Chromium вычисляет текущее состояние всех активных CSS-анимаций (@keyframes) и transition. Для этого он берёт текущий timestamp, учитывает duration, delay, easing-функции и timeline, после чего интерполирует значения свойств между ключевыми кадрами. В результате получаются конкретные вычисленные значения стилей для текущего кадра.
После завершения этих вычислений элементы помечаются dirty-флагами. Уже на следующей фазе — style — браузер пересчитывает стили только для изменённых узлов.
Фаза animate размещена перед style и layout не случайно: это позволяет собрать все изменения от анимаций заранее и обработать их за один проход, избегая лишних пересчётов.
Style
Фаза style отвечает за пересчёт стилей и всегда выполняется в основном потоке. Её задача — собрать все изменения, накопленные на предыдущих этапах (парсинг, выполнение скриптов, анимации), и превратить их в итоговые вычисленные стили элементов.
Chromium не пересчитывает стили для всего дерева целиком. Он использует систему dirty-флагов: когда что-то меняется — класс, inline-стиль, DOM-структура или результат анимации — элемент и его предки помечаются как «грязные». Пересчёт выполняется только для этих ветвей.
Далее для каждого такого элемента собираются подходящие CSS-правила из CSSOM с учётом каскада, специфичности и наследования. После этого формируется итоговый computed style.
Важно, что селекторы индексируются по последнему простому селектору — тегу, классу или id. Поэтому сопоставление идёт справа налево, что на практике оказывается наиболее эффективным.
В конце этой фазы все «грязные» элементы имеют актуальные computed styles, и пайплайн переходит к layout.
Layout
На этапе layout браузер превращает DOM и вычисленные стили в конкретные размеры и позиции элементов на экране.
Для этого используются разные алгоритмы разметки: обычный flow layout, flexbox и grid. Каждый из них работает по принципу взаимодействия родителей и потомков: родитель передаёт дочернему элементу ограничения (например, доступную ширину), а тот, опираясь на них и свои стили, вычисляет размеры.
Блочный layout обычно укладывается в один проход, а flex и grid требуют нескольких этапов. Сначала вычисляются естественные размеры элементов, затем выполняется проход размещения. Раньше при глубокой вложенности таких контейнеров сложность могла расти экспоненциально. В современной архитектуре Chromium эта проблема решена с помощью явного кэширования промежуточных результатов.
Итогом фазы layout становится неизменяемое дерево фрагментов (fragment tree), в котором каждый фрагмент хранит размеры и позицию элемента. После создания фрагменты не модифицируются, а также в дереве нет ссылок «вверх» и передачи данных от родителя к потомку. Благодаря этому при следующем обновлении можно переиспользовать большую часть дерева, пересчитывая только изменённые ветви.
Текстовый и инлайн-контент хранится отдельно — в виде плоского списка. Это ускоряет обход и снижает расход памяти, что особенно важно для рендеринга текста.
Pre-paint
Фаза pre-paint следует сразу после layout. На этом этапе выполняется обход дерева фрагментов с двумя основными целями.
Первая — paint invalidation. На предыдущих фазах элементы помечаются как изменённые, и именно pre-paint определяет, какие области экрана нуждаются в перерисовке.
Вторая цель — построение property trees.
Property trees представляют собой четыре отдельных дерева: transform, clip, effect и scroll. В них присутствуют только те элементы, которые реально создают соответствующие эффекты. Структура этих деревьев отражает не сам DOM, а отношения «контейнер → потомок» между визуально значимыми узлами.
- Transform tree хранит всё связанное с позицией и движением элемента: смещение, CSS-трансформации, perspective и scroll translation.
- Clip tree описывает все виды обрезки: clip-path, overflow clip, обрезку по border-radius.
- Effect tree хранит визуальные эффекты: opacity, фильтры, маски.
- Scroll tree отвечает за цепочки прокрутки.
Между деревьями существуют перекрёстные ссылки, указывающие на относительный порядок применения эффектов разных типов. Каждый DOM-элемент имеет свой property tree state — набор из четырёх ссылок на соответствующие узлы. Именно он позволяет точно определить положение элемента и способ его отрисовки.
Scroll
Фаза scroll — одна из немногих, которая может полностью выполняться в композитном потоке, минуя основной. Её главная цель: обеспечить плавный скроллинг даже тогда, когда основной поток занят тяжёлым JavaScript или другими задачами.
Обновление scroll offset сводится к изменению одного узла в transform tree, а все потомки автоматически сдвигаются вместе с ним. Именно поэтому скроллинг дёшев — ни layout, ни pre-paint, ни paint не задействованы.
В некоторых случаях скролл не может быть обработан на композиторе — например, при наличии синхронных обработчиков touch-событий. Тогда событие передаётся в основной поток. Такие ситуации называются slow scroll, в отличие от fast scroll в композитном потоке.
Paint
Фаза paint следует сразу после scroll. Её задача — превратить дерево фрагментов и property trees в плоский список команд рисования, который позже можно отрастеризовать в текстуры на GPU.
Этот список называется display list, а его атомарная единица — display item. Каждый display item представляет собой одну конкретную операцию: отрисовку фона, текста, границ и других визуальных элементов.
Каждый display item создаётся определённым объектом из дерева фрагментов. Кроме того, при создании ему присваивается текущий property tree state — та самая четвёрка (transform, clip, effect, scroll), которую мы рассматривали ранее. Именно она определяет, в каком пространстве координат и с каким набором эффектов нужно растеризовать данный элемент.
После формирования display list он разбивается на paint chunks — группы соседних display items с одинаковым property tree state. Границы между чанками проходят там, где состояние меняется. Например, если одно поддерево прокручивается, а соседнее — нет, они окажутся в разных чанках.
Каждый paint chunk является потенциальным кандидатом для отдельного composited layer на следующей фазе — layerize. Чанки служат основной единицей гранулярности для raster invalidation: при изменениях система сравнивает новые чанки со старыми и определяет, какие области нужно перерастеризовать.
Commit
Commit — это фаза синхронизации между основным и композитным потоками.
До этого момента вся работа — style, layout, pre-paint и paint — выполняется на основном потоке и оперирует такими структурами данных, как дерево фрагментов, property trees и display list. Композитный поток, в свою очередь, работает со своей копией этих данных. Commit — единственная точка, где эти два мира синхронизируются: данные из основного потока атомарно копируются в композитный. Для этого основной поток блокируется — он останавливается и ждёт завершения копирования. Сам commit — относительно дешёвая операция и обычно занимает несколько миллисекунд. Однако его нельзя прервать посередине, иначе композитный поток получил бы несогласованное состояние.
Все скопированные данные попадают не сразу в «живое» дерево, а в так называемый pending tree — промежуточную структуру. Pending tree существует для обеспечения атомарности визуальных изменений. Если за один кадр произошло несколько мутаций — сдвиг элемента, изменение фона, отрисовка на canvas — пользователь должен увидеть их одновременно, а не по очереди.
После завершения commit основной поток разблокируется и может начинать подготовку следующего кадра.
Ещё немного про animate
Фаза animate формально располагается в начале рендеринг-пайплайна — перед style — но по своей природе она отличается от остальных фаз. Она может выполняться как на основном потоке, так и целиком на композитном, и именно это разделение играет ключевую роль для производительности.
В Chromium существует два типа анимаций.
Первый тип — анимации основного потока. Они мутируют свойства, влияющие на layout, например width, height или left. Такие анимации работают через стандартный цикл: на каждом кадре движок вычисляет текущее значение, помечает элемент как «грязный», после чего запускается полный пайплайн: style → layout → pre-paint → paint.
Второй тип — анимации, которые могут полностью обходить основной поток. Кандидатами на ускорение являются анимации, затрагивающие свойства transform, opacity, filter и backdrop-filter. Эти свойства представлены в property trees в виде узлов transform и effect и могут мутироваться в композитном потоке без пересчёта layout.
Часть 4. Стадии композитного потока и работа с GPU.
Layerize
Как мы уже видели раньше, композитный поток работает со своей копией данных из property trees (четырёх деревьев: transform, clip, effect и scroll) и display list — списка команд для рисования. При этом display list уже разбит на paint chunks — группы соседних команд с одинаковым состоянием property trees. Границы между чанками проходят в тех местах, где состояние меняется. Например, если одно поддерево прокручивается, а соседнее — нет, они окажутся в разных чанках.
Фаза layerize превращает плоский список paint chunks в иерархию композитных слоёв (composited layers). Эти слои будут растеризовываться независимо друг от друга, а затем собираться GPU в финальную картинку. На вход layerize получает упорядоченный список paint chunks с их состояниями property trees, а на выходе формирует набор объектов-слоёв. Каждый такой слой содержит часть display items и соответствующий фрагмент property trees.
На этом этапе браузер решает важную компромиссную задачу. С одной стороны, можно было бы объединить все paint chunks в один огромный слой и растеризовать всё целиком, но тогда при любом изменении пришлось бы полностью перерисовывать сцену. С другой стороны, можно было бы создать отдельный слой для каждого чанка, но это быстро привело бы к перерасходу GPU-памяти. Layerize балансирует между этими крайностями и создаёт слои только там, где это действительно даёт выигрыш в производительности.
Алгоритм layerize работает в два шага. Сначала для каждого paint chunk создаётся объект PendingLayer — кандидат на отдельный слой. Затем алгоритм пытается объединять соседние PendingLayer в один слой, если это возможно. Объединение может быть запрещено, например, в следующих случаях:
- чанк имеет явные причины находиться в отдельном слое: элемент анимируется на композитном потоке или использует
will-change; - объединение приведёт к большому количеству пустого пространства: чанки находятся далеко друг от друга, и между ними появится «пустой» слой, который зря тратит память.
После того как финальный список PendingLayer сформирован, для каждого создаётся настоящий композитный слой. Этот слой уже живёт в пространстве композитного потока и содержит записанную последовательность команд отрисовки, которая позже будет растеризована в текстуры.
Raster, decode & paint worklets
Raster — это этап, на котором display lists превращаются в реальные пиксели, записанные в GPU-текстуры. Каждый композитный слой разбивается на квадратные тайлы, и растеризация происходит по тайлам. Тайлы сортируются по приоритету: сначала обрабатываются те, что находятся в текущем viewport, затем те, которые скоро понадобятся при прокрутке, и только потом остальные. Сама растеризация выполняется на GPU в viz process с помощью Skia, чтобы не блокировать ни основной поток, ни композитный.
Decode — это отдельная задача, которая часто работает параллельно с растеризацией. Изображения (JPEG, PNG и другие) хранятся в display list в сжатом виде, чтобы не увеличивать объём данных при передаче с основного потока. Декодирование — достаточно тяжёлая операция, и выполнять её на композитном потоке означало бы просадки FPS. Поэтому в Chromium декодирование вынесено в отдельные worker-потоки.
Paint worklets — это часть CSS Houdini, которая позволяет разработчикам писать собственный код для генерации графики. Когда compositor растеризует тайл с элементом, использующим paint worklet, он вызывает код worklet, получает результат и встраивает его в текстуру. Важно, что paint worklet может вызываться много раз — при изменении размеров элемента или CSS-переменных — поэтому его код должен быть максимально лёгким.
Activate
Во время фазы commit данные с основного потока попадают не сразу в «живое» дерево слоёв, а во временное pending tree. Фаза activate — это момент, когда pending tree становится active tree.
Chromium всегда поддерживает как минимум два дерева слоёв на композитном потоке:
- active tree — используется для генерации кадров прямо сейчас;
- pending tree — содержит обновления с основного потока и растеризуется в фоне.
Это разделение нужно для того, чтобы пока pending tree обрабатывается, active tree мог продолжать генерировать кадры для скролла и анимаций. Активация происходит только тогда, когда все видимые тайлы pending tree полностью готовы. До этого момента браузер продолжает рисовать старую версию сцены, даже если она уже устарела.
Процесс activate похож на commit, но работает целиком внутри композитного потока — данные переносятся с pending tree на active tree. Это атомарная операция: пользователь либо видит полностью обновлённый кадр, либо всё ещё старый, без промежуточных состояний. После активации pending tree освобождается и используется для следующего обновления.
Результатом фазы activate становится compositor frame — набор инструкций для отрисовки всей сцены, разбитой на render pass. Каждый render pass содержит упорядоченный список quads — примитивов рисования. Каждый quad ссылается на GPU-текстуру, задаёт координаты, трансформации и эффекты. Чаще всего это texture quads с растеризованными тайлами с предыдущих этапов, но также бывают solid color quads (сплошная заливка цветом) и video quads. Готовый compositor frame отправляется в viz process для дальнейшей обработки.
Aggregate
Aggregate — это фаза, на которой compositor frames из разных источников объединяются в один итоговый кадр, готовый к отображению.
В современном Chrome существует несколько независимых источников compositor frames:
- render processes создают кадры для вкладок и iframe;
- browser process создаёт кадры для UI браузера.
Все они отправляют свои compositor frames в единый viz process. Каждый frame получает уникальный id, и другие compositor frames могут ссылаться на него через SurfaceDrawQuad.
Агрегация работает рекурсивно. Алгоритм начинает с корневого frame (обычно UI браузера или основной страницы вкладки) и проходит по всем quads в порядке отрисовки. Если quad обычный — texture или solid color — он просто копируется в итоговый compositor frame. Если quad — SurfaceDrawQuad, агрегатор находит соответствующий compositor frame и рекурсивно встраивает его содержимое. Во время этого процесса также выполняются оптимизации: например, если iframe полностью за пределами экрана, его quads можно вообще не добавлять.
В результате получается единый compositor frame со всеми quads, выровненными в общей системе координат экрана.
Draw
Draw — это финальная фаза, на которой aggregated compositor frame превращается в реальные GPU-команды.
Viz process использует несколько backend-реализаций для работы с GPU. Основной современный backend — SkiaRenderer. Он проходит по всем render pass внутри aggregated frame и по каждому quad генерирует команды отрисовки.
Для SkiaRenderer процесс состоит из двух этапов. Сначала формируются Deferred Display Lists (DDL) — структуры Skia, в которых записываются команды отрисовки, но они ещё не выполняются на GPU. Для каждого quad вызывается соответствующая Skia-команда, и она добавляется в DDL. Когда все DDL готовы, они передаются на GPU main thread в viz process. Этот поток — единственный, который напрямую общается с GPU-драйвером. Skia проигрывает DDL и превращает их в реальные GPU-инструкции.
Что гарантированно создаёт композитный слой
Исходя из архитектуры пайплайна и работы layerize, можно выделить элементы DOM, которые почти гарантированно получат собственный composited layer и будут растеризовываться отдельно. Это важно учитывать при оптимизации: независимые слои ускоряют анимации и скролл, но их избыток увеличивает расход памяти и накладные расходы.
Причины создания слоя
- 3D transforms и perspective: Элементы с
transform: translateZ(),rotateX(),rotateY()илиperspectiveполучают отдельный слой, чтобы трансформации можно было применять без перерисовки содержимого. - Compositor-анимируемые свойства: Анимации
transform,opacity,filter,backdrop-filter, включаяwill-change, создают слой автоматически. - Video и Canvas:
<video>и<canvas>получают слой, так как их содержимое обновляется независимо от layout и может использоваться как GPU-текстура. - Overflow scrolling: Элементы с
overflow: scrollилиautoи реальным скроллом получают слой для обработки прокрутки на compositor thread. - position: fixed и position: sticky: Такие элементы меняют позицию при скролле, и compositor может обновлять их transform без пересчёта layout.
- Iframe: Каждый
<iframe>, особенно из другого origin, получает слой из-за изоляции и безопасности. - Элементы с composited descendants: Если потомок требует слоя, родитель часто тоже становится composited.
- CSS filters и backdrop-filter: Элементы с фильтрами часто выносятся в отдельный слой.
Что не создаёт слой автоматически
- Обычные CSS свойства, например
color,background-color,border,width,height— они требуют полного цикла. - Анимации не-compositor свойств (например,
width,left,top) — они анимируются на основном потоке и пересчитывают layout каждый кадр. - Элементы с
z-indexсами по себе —z-indexвлияет только на порядок отрисовки, но не создаёт слой без других причин. - Абсолютное позиционирование (
position: absolute) без других триггеров — оно не меняется при скролле viewport, так что не требует слоя.
Практические рекомендации:
- Используйте
will-change: transformилиtransform: translateZ(0)только для элементов, которые реально будут анимироваться — избыточные слои тратят память. - Проверяйте количество слоёв через DevTools → три точки → More Tools → Layers.
- Там же можно посмотреть, по какой причине тот или иной элемент был вынесен в отдельный слой (Конкретный слой → Details → Compositing Reasons).
Часть 5. Рендеринг в React.
В прошлых частях мы рассмотрели, как работает рендеринг в браузере на примере Chromium. В этой части обсудим, как работает рендеринг компонентов уже внутри React, и какие подходы использует React, чтобы делать его быстрым и неблокирующим.
Элементы, компоненты и виртуальный DOM
Когда разработчик пишет JSX, под капотом инструмент сборки (например Babel или esbuild) компилирует его в вызовы React.createElement. Выражение <Button color="blue" /> превращается в React.createElement(Button, { color: "blue" }), результатом которого является простой JavaScript-объект — React-элемент. Это не экземпляр компонента и не DOM-узел, а лишь описание того, что нужно отрендерить: тип, пропсы и дочерние элементы. Эти элементы пересоздаются заново при каждом рендере, но на их основе React работает с совершенно другой структурой данных, которая живёт значительно дольше.
Раньше эта структура называлась «виртуальный DOM», однако начиная с 16 версии команда React отказалась от этого определения. Причина в том, что React работает не только с DOM, например, есть React Native. Структура, которая используется всеми платформами, одинаковая, но реальную работу по отрисовке на платформе выполняет уже конкретный renderer. Поэтому говорить про «виртуальный DOM» как про универсальную концепцию не совсем корректно — правильнее говорить о дереве fiber-узлов.
Fiber-узел: виртуальный стековый фрейм
Fiber — это обычный JavaScript-объект, который является основной единицей работы в React с версии 16. Каждому компоненту в дереве соответствует свой fiber-узел, и в отличие от React-элементов, которые пересоздаются на каждый рендер, fiber-узлы мутируют и живут столько, сколько живёт компонент. Так React не воссоздаёт всё дерево заново, а обновляет существующие узлы.
Каждый fiber-узел хранит в себе достаточно много информации: например, тип компонента (type), его пропсы в двух вариантах — pendingProps (те, что будут использованы в текущем рендере) и memoizedProps (те, что были использованы в последнем завершённом рендере). Хуковое состояние функциональных компонентов хранится в memoizedState в виде связного списка, где каждый узел соответствует одному вызову хука. Очередь запланированных обновлений находится в updateQueue.
Посмотреть на объект fiber можно через DOM-элемент компонента в консоли вашего браузера, например:
const el = document.getElementById('root').firstChild;
const fiberKey = Object.keys(el).find(k => k.startsWith('__reactFiber'));
const fiber = el[fiberKey];
console.log(fiber);

Для навигации по дереву fiber использует три указателя: child — на первого потомка, sibling — на следующего брата, и return — на родителя. Такая структура позволяет обходить дерево итеративно без рекурсии — именно это стало ключевым техническим решением, которое отличает Fiber от предыдущего Stack Reconciler.
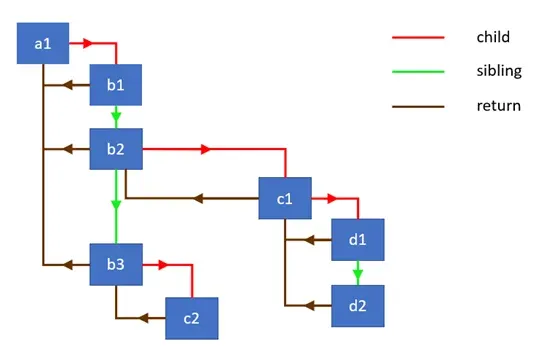
Прежний Stack Reconciler использовал простую рекурсию и при обходе дерева полагался на встроенный стек вызовов JavaScript, который невозможно прервать: начавшись, рекурсия обязана дойти до конца. Fiber позволил отказаться от рекурсии, и теперь React управляет обходом сам: может отложить, приостановить или отменить его в любой момент.
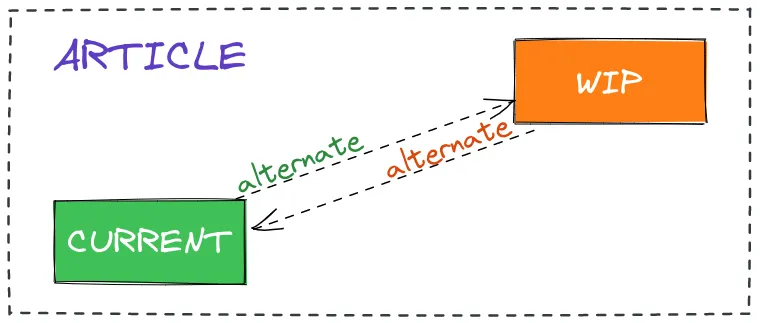
Двойная буферизация: current и workInProgress
React всегда поддерживает в памяти не одно, а два дерева fiber-узлов. Первое называется current — это дерево, которое сейчас отображается на экране. Второе называется workInProgress — дерево, над которым ведётся работа в данный момент. Когда приходит обновление, React не изменяет current-дерево напрямую, а строит новое workInProgress-дерево, клонируя существующие узлы через поле alternate. Каждый fiber-узел в current-дереве содержит указатель alternate на свой двойник в workInProgress-дереве, и наоборот. Когда работа завершена и наступает момент применить изменения к DOM, React просто переставляет указатели: workInProgress-дерево становится новым current, а старое current превращается в заготовку для следующего workInProgress. Эта техника называется двойной буферизацией и именно она гарантирует, что пользователь никогда не увидит промежуточное, рассогласованное состояние интерфейса.
При обновлениях React старается максимально переиспользовать существующие fiber-узлы. Если у узла нет изменений, React может применить оптимизацию — пропустить его и всё поддерево полностью, что значительно сокращает объём работы. Именно на этом принципе работают React.memo, useMemo и shouldComponentUpdate: они помогают React как можно чаще принимать решение об оптимизации.
Work Loop: beginWork и completeWork
Обход дерева происходит внутри цикла while. Цикл берёт текущий workInProgress-узел и вызывает для него performUnitOfWork. Внутри этой функции происходят две вещи. Сначала вызывается beginWork — функция, которая отвечает за нисходящую часть обхода: она вызывает функцию компонента или метод render, сравнивает полученный результат с предыдущим, создаёт или обновляет дочерние fiber-узлы и возвращает ссылку на следующего потомка. Если потомок есть, work loop переходит к нему и повторяет процесс. Как только beginWork возвращает null, достигнут листовой узел дерева — дальше идти некуда.
В этот момент вызывается completeWork — восходящая часть обхода. Для узлов, которые соответствуют DOM-элементам, именно здесь создаётся или обновляется реальный DOM-узел — но не добавляется в документ, а лишь подготавливается в памяти. Узлы, которые требуют каких-либо изменений (вставка, обновление, удаление, вызов эффектов), помечаются флагами. После завершения completeWork узел поднимается к родителю через указатель return, либо work loop переходит к братскому узлу через sibling. Таким образом, обход идёт по принципу «сначала в глубину, потом вправо, потом вверх».
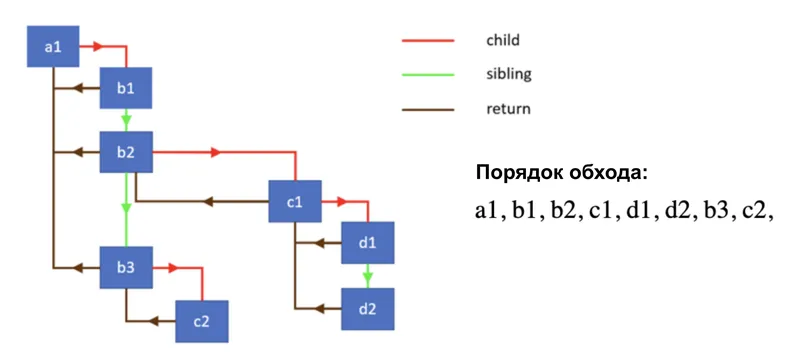
Планировщик и система приоритетов Lanes
Не все обновления одинаково важны, и React это понимает. Система приоритетов в современных версиях React реализована через механизм Lanes — битовую маску, представляющую одновременно приоритет и группу обновлений. Чем меньше численное значение лейна, тем выше приоритет: клик пользователя имеет значение 0b0000000000000000000000000001000, а фоновые переходы (transitions) — 0b0000000001111111111111100000000. Когда React решает, с чего начинать работу, он вызывает getNextLanes, которая возвращает набор лейнов с наивысшим приоритетом.
Планировщик работы принимает колбэк и уровень приоритета, и запускает задачу в подходящий момент. Когда React начинает работу над деревом, он проверяет специальный флаг от планировщика внутри work loop — и если планировщик сигнализирует, что время вышло и нужно уступить поток браузеру, цикл прерывается. Работа сохраняется в workInProgress-дереве и возобновляется при следующем вызове. Именно так достигается прерываемость рендеринга. При этом если обновление попало в BlockingLane (например, синхронный вызов из обработчика события), React выполняет работу до конца без прерываний.
Commit Phase: три прохода по дереву
Когда render phase завершена и workInProgress-дерево полностью построено, начинается commit phase — она всегда синхронна и не может быть прервана. Прерывание здесь недопустимо: если применить половину изменений и остановиться, пользователь увидит рассогласованный интерфейс. Commit phase в исходном коде React состоит из трёх последовательных проходов по дереву, каждый из которых отвечает за свой класс работ.
На первом проходе вызывается, например, getSnapshotBeforeUpdate у классовых компонентов и выполняются некоторые другие операции.
Второй проход — это и есть собственно изменение DOM: вставка, обновление атрибутов, удаление узлов, обновление ref'ов. Именно в конце этого прохода происходит и смена указателей: root.current переключается с бывшего current-дерева на workInProgress, которое с этого момента становится новым current.
Третий проход запускает useLayoutEffect и его аналоги у классовых компонентов. Всё это выполняется в рамках одного синхронного таска JavaScript, именно поэтому useLayoutEffect уже использует новые значения DOM, но браузер ещё не успел их фактически отрисовать.
После этого, уже асинхронно через браузерное API MessageChannel, запускаются пассивные эффекты из useEffect. Такое разделение не случайно: useLayoutEffect выполняется синхронно до того, как браузер успел отрисовать изменения, поэтому он подходит для измерений DOM, а useEffect — для операций, которые могут подождать.
Как это знание применять на практике
Понимание того, как устроен Fiber изнутри, помогает принимать более осознанные решения. Когда компонент рендерится, React вызывает его функцию, получает React-элементы, затем reconciler сравнивает их с соответствующими fiber-узлами и решает, нужна ли реальная работа. Лишний рендер функции компонента — это дёшево; лишнее изменение DOM — дорого. Поэтому оптимизации вроде React.memo имеют смысл тогда, когда компонент рендерится часто, а его пропсы меняются редко — в этом случае React применяет оптимизацию и не тратит время на beginWork для всего поддерева. Для тяжёлых обновлений, которые не требуют немедленного отклика, useTransition позволяет явно поместить работу в TransitionLanes — и тогда React сможет прервать этот рендер, если появится более срочное обновление, например ввод пользователя. Fiber даёт React полный контроль над тем, когда и в каком порядке выполнять работу — и именно это лежит в основе всей современной архитектуры React.
Часть 6. Альтернативные пути рендеринга.
На протяжении всего исследования мы говорили об одном сценарии рендеринга — браузер получает HTML/CSS/JS и строит DOM. Однако появление пикселей на экране не ограничивается только этим. В этой заключительной части мы рассмотрим альтернативные пути и технологии и сделаем обзор всего, что может быть доступно, когда мы говорим об отрисовке какого-то контента.
SSR: рендеринг на сервере
Server-Side Rendering — это метод создания веб-страниц, при котором готовый HTML-код генерируется на сервере, а не в браузере пользователя. Ещё до эпохи SPA (single page application) именно сервер генерировал HTML и отдавал его браузеру. Сегодня SSR снова популярен, но уже в новой оболочке, благодаря фреймворкам вроде Next.js и Nuxt.
Как это работает:
- Браузер делает запрос к серверу.
- Сервер запускает JavaScript (Node.js, Deno, Bun), исполняет компоненты и генерирует строку HTML.
- Готовая разметка отправляется клиенту, и браузер может немедленно отрисовать страницу.
- Параллельно или после загружается JS-бандл, и происходит гидратация (hydration) — React/Vue «оживляют» уже существующий DOM, навешивая обработчики событий.
Какие преимущества даёт SSR:
- Уменьшается время до отрисовки первого экрана (FCP/LCP), т.к. пользователь видит контент до загрузки, парсинга и исполнения JS.
- Поисковые боты получают готовый HTML без необходимости выполнять JavaScript, таким образом улучшая SEO-индексацию приложения.
- Страница доступна и работает даже при отключённых скриптах.
Гидратация — это дорогой процесс. Браузер получает HTML от сервера, но потом ему всё равно приходится «сверять» его с виртуальным DOM React. Если серверный и клиентский вывод расходятся, React перестраивает DOM заново. Поэтому некоторое время назад стала набирать популярность островная архитектура (Islands Architecture). Имплементацией этого подхода можно считать и React Server Components — механизм, когда гидрируются только интерактивные «острова», так называемые «клиентские компоненты», а «серверные компоненты» остаются статическим HTML.
Canvas: 2D-графика
<canvas> — прямоугольник с программируемым растровым содержимым. В отличие от DOM, canvas не имеет дерева объектов: мы рисуем напрямую через Canvas API.
const canvas = document.querySelector('canvas');
const ctx = canvas.getContext('2d');
ctx.fillStyle = '#ff6b6b';
ctx.fillRect(10, 10, 100, 50); // прямоугольник
ctx.font = '24px serif';
ctx.fillText('Hello, Canvas!', 10, 100); // текст
Команды вроде fillRect — это инструкции нарисовать что-то на canvas прямо сейчас. После выполнения они не оставляют никакого связного объекта в памяти. Нельзя «выбрать» нарисованный прямоугольник и сдвинуть его. Чтобы «переместить» объект, нужно очистить canvas и нарисовать всё заново.
Вызов canvas.getContext('2d') возвращает объект CanvasRenderingContext2D — в случае Chromium это обёртка над Skia. Когда мы вызываем ctx.fillRect(...), JavaScript-вызов транслируется в команду Skia.
Буфер пикселей — блок в памяти, который выделяет браузер для canvas. Его размер вычисляется как ширина × высота × 4 байта (RGBA: красный, зелёный, синий, прозрачность). Например, для canvas 800×600 это ~1.9 МБ. Skia пишет результат рисования прямо в этот буфер.
Дальше этот буфер должен попасть на экран, и здесь canvas также встраивается в браузерный пайплайн, который мы разбирали в предыдущих частях. Canvas-элемент становится отдельным композитным слоем и передаётся compositor'у. Compositor, в свою очередь, уже компонует его с остальной страницей.
Главная проблема canvas — он живёт в главном потоке браузера. Сложный цикл рисования (игра или редактор) конкурирует за процессорное время с обработкой пользовательского ввода, выполнением JS и другими операциями.
OffscreenCanvas помогает решить эту проблему: благодаря этому холст можно передавать в Web Worker, и весь рендеринг будет происходить в отдельном потоке.
// Главный поток
const offscreen = canvas.transferControlToOffscreen();
worker.postMessage({ canvas: offscreen }, [offscreen]);
// Web Worker
self.onmessage = ({ data }) => {
const ctx = data.canvas.getContext('2d');
// Рисуем здесь, не мешая главному потоку
};
Canvas используется везде, где DOM становится узким местом: 2D-игры, редакторы изображений, графики.
SVG: векторный рендеринг
SVG (Scalable Vector Graphics) — XML-формат для векторной графики, полностью интегрированный в DOM. В отличие от canvas, где вы работаете с пикселями напрямую, SVG описывает намерения: «нарисуй окружность радиуса 50 в точке (100, 100)». Браузер сам решает, как именно превратить это в пиксели — и делает это каждый раз заново при необходимости. Именно поэтому SVG выглядит одинаково чётко и на экране ноутбука, и на 4K-мониторе, и распечатанным на бумаге.
Каждый SVG-элемент — <path>, <circle>, <rect>, <text> — это полноценный DOM-узел. Браузер строит для SVG такое же дерево, как для HTML, применяет к нему CSS-стили (включая анимации и переходы), отслеживает события мыши и клавиатуры. Это даёт огромную гибкость: можно написать document.querySelector('circle').setAttribute('r', 80) и окружность сразу изменит размер. Можно повесить addEventListener('click', ...) на отдельный <path>. Скрин-ридеры могут читать <title> и <desc> внутри SVG.
Когда браузер встречает SVG, процесс рендеринга идёт через те же стадии, что и для обычного HTML, которые мы разбирали в предыдущих частях — только со своей спецификой на каждом шаге.
SVG-разметка парсится в узлы SVGElement. Каждый элемент несёт геометрические атрибуты (cx, cy, r, d) и стилевые (fill, stroke, opacity). Атрибут d у <path>, например M 10 10 L 100 50 C 150 80 200 20 250 50 Z — это последовательность команд «переместись», «нарисуй линию», «нарисуй кривую Безье», «закрой контур».
В отличие от HTML-layout, где браузер вычисляет потоковую раскладку элементов, SVG использует систему координат пользователя (user coordinate system). Атрибут viewBox="0 0 200 200" задаёт внутреннюю систему координат, а реальный размер элемента на странице определяется атрибутами width/height или CSS. Браузер вычисляет матрицу трансформации, которая переводит из одной системы в другую, и применяет её ко всей сцене.
Если SVG-элемент анимируется через CSS transform или opacity, браузер может вынести его на отдельный композитный слой — точно так же, как для обычных HTML-элементов. В этом случае повторная растеризация не нужна: compositor просто применяет трансформацию к уже готовой текстуре. Но если анимируется d (форма пути) или fill (заливка) — это смена геометрии, и браузер будет растеризовать её заново на каждом кадре.
SVG хорош для иконок, иллюстраций, интерактивных диаграмм. Но при тысячах элементов DOM-дерево становится узким местом — тогда переходят на canvas или WebGL.
WebGL и WebGPU: GPU в браузере
Canvas и SVG не подходят, если нужна настоящая 3D-сцена с тысячами объектов, динамическим освещением и 60 FPS. Здесь в дело вступает WebGL — браузерный интерфейс для прямого программирования видеокарты.
Идея проста: CPU (процессор) хорош в последовательных сложных вычислениях, а GPU (видеокарта) — в параллельных простых. Современная GPU имеет тысячи небольших ядер, которые могут одновременно обрабатывать тысячи пикселей или вершин. WebGL — это мост между JavaScript и GPU.
Шейдер — это программа, которая выполняется не на CPU, а прямо на GPU. Вы пишете её на специальном языке GLSL (Graphics Library Shader Language), который синтаксически похож на C. Шейдеры бывают двух видов, и они работают в паре.
- Вершинный шейдер (vertex shader) запускается один раз для каждой вершины геометрии. Его задача — сказать GPU, где именно на экране должна оказаться эта вершина. Любой 3D-объект состоит из треугольников, а каждый треугольник — из трёх вершин с координатами в трёхмерном пространстве. Вершинный шейдер принимает 3D-координату и превращает её в 2D-координату на экране с учётом положения камеры, перспективы и трансформаций объекта.
- Фрагментный шейдер (fragment shader) запускается один раз для каждого пикселя, который покрывает треугольник. Его задача — сказать GPU, какого цвета должен быть этот пиксель. Именно здесь реализуются освещение, тени, текстурирование и отражения.
Мы не будем подробно останавливаться на том, как работать с WebGL. Отметим только, что WebGL использует canvas.
<canvas id="gl-canvas" width="640" height="480"></canvas>
const canvas = document.querySelector("#gl-canvas");
const gl = canvas.getContext("webgl");
WebGL-canvas — это тот же композитный слой. Compositor читает результат рендеринга этого слоя как обычную текстуру при финальной сборке страницы.
Писать на сыром WebGL — многословно и непросто: десятки строк на каждую операцию. Именно поэтому существуют высокоуровневые библиотеки, такие как Three.js.
WebGPU — преемник WebGL, разработанный с нуля для современных GPU API. Он частично доступен в большей части браузеров. В первую очередь благодаря этому инструменту GPU теперь можно использовать не только для графики, но и для общих вычислений (GPGPU) — машинное обучение, обработка данных и т.д.
PDF: рендеринг для печати
Когда вы открываете PDF в браузере, он не просто «отображает картинку». Браузеру нужно исполнить целый язык программирования.
PDF (Portable Document Format) вырос из PostScript — языка описания страниц, разработанного Adobe в 1980-х для управления принтерами. PostScript был полноценным языком программирования: принтер буквально выполнял код, который говорил ему, как именно рисовать страницу. PDF — это упрощённая, но похожая система.
Когда вы открываете PDF в Chrome, работает библиотека PDFium, написанная на C++. Она напрямую обращается к системным шрифтам, использует Skia для растеризации, а результат compositor получает как обычную текстуру.
PDF.js — принципиально другой подход: Mozilla реализовала полный PDF-рендерер на чистом JavaScript. Это означает, что весь парсинг, интерпретация операторов, управление шрифтами и растеризация происходят в JavaScript-движке браузера, а результат рисуется через Canvas API.
Конвертировать из HTML в PDF браузер умеет через window.print() и диалог печати. Внутри происходит примечательное: браузер запускает отдельный проход рендеринга с другими правилами (CSS @media print, разбивка на страницы). Chromium передаёт результат в PDFium, который уже отрисовывает контент.
Рендеринг видео
Элемент <video> с точки зрения compositor'а — это отдельный слой. Compositor не ждёт, пока браузер перерисует DOM — он получает свежие видеокадры напрямую из декодера и компонует их в финальное изображение независимо от остальной страницы. Это означает, что видео продолжает воспроизводиться плавно, даже если главный поток браузера занят тяжёлым JavaScript.
Синхронизация видео и аудио — это отдельная задача. Браузер поддерживает presentation timestamp каждого кадра: момент времени, в который его нужно показать. Аудио идёт через отдельный AudioContext с собственными буферами и таймингом. Если декодер отстаёт (например, сложная сцена с быстрым движением), браузер может намеренно пропустить кадр, чтобы не рассинхронизироваться с аудио — мы видим это как резкий скачок вместо плавного движения.
Долгое время JavaScript не мог ни кодировать, ни декодировать видео прямо в браузере напрямую. WebCodecs API добавил эту возможность: теперь доступны VideoDecoder и VideoEncoder — прямые обёртки над аппаратными кодеками, без промежуточных слоёв. Благодаря этому, в частности, появилась возможность делать полноценные видеоредакторы прямо в браузере.
Заключение
Мы начали с браузерных движков и проследили путь от исходного кода до пикселей на экране: через построение DOM, стили, layout, paint, слои, compositor и GPU. Увидели, как React оптимизировал работу через Fiber. И наконец, убедились, что «рендеринг» — понятие куда шире одного конвейера.
Браузер — это удивительная инженерная система. Надеюсь, это исследование помогло сделать её чуть менее загадочной.